Archives: WP version of published papers
- Forecasting with Panel Data: Estimation Uncertainty Versus Parameter Heterogeneity, by M. Hashem Pesaran, Andreas Pick and Allan Timmermann, March 2022, Cambridge Working Papers in Economics, CWPE2219
- High-Dimensional Forecasting with Known Knowns and Known Unknowns, by M. Hashem Pesaran and Ron P. Smith, February 2024, Cambridge Working Papers in Economics, CWPE2406
- Pooled Bewley Estimator of Long Run Relationships in Dynamic Heterogenous Panels, by Alexander Chudik, M. Hashem Pesaran, and Ron P. Smith, May 2021
- Causal Effects of the Fed's Large-Scale Asset Purchases on Firms' Capital Structure, by Andrea Nocera and M. Hashem Pesaran, April 2022, Cambridge Working Papers in Economics, CWPE2224
- Revisiting the Great Ratios Hypothesis, by Alexander Chudik, M. Hashem Pesaran and Ron P. Smith, March 2022, Cambridge Working Papers in Economics, CWPE2215 and CESifo Working Paper No. 9625
- Short T Dynamic Panel Data Models with Individual, Time and Interactive Effects, by Kazuhiko Hayakawa, M. Hashem Pesaran and L. Vanessa Smith, September 2018, revised July 2021
- Factor Strengths, Pricing Errors, and Estimation of Risk Premia, by M. Hashem Pesaran and Ron P. Smith, March 2021, CESifo Working Paper No. 8947
- COVID-19 Time-varying Reproduction Numbers Worldwide: An Empirical Analysis of Mandatory and Voluntary Social Distancing, by Alexander Chudik, M. Hashem Pesaran and Alessandro Rebucci, March 2021
- Identification and Estimation of Categorical Random Coeficient Models, by Zhan Gao and M. Hashem Pesaran, April 2022, Cambridge Working Papers in Economics, CWPE2228
- Testing for Alpha in Linear Factor Pricing Models with a Large Number of Securities, by M. Hashem Pesarann and Takashi Yamagata, March 2017, revised January 2018
- Reflections on "Testing for Unit Roots in Heterogeneous Panels", by Kyung So Im, M. Hashem Pesaran and Yongcheol Shin, January 2023, Cambridge Working Papers in Economics, CWPE2310
- Variable Selection and Forecasting in High Dimensional Linear Regressions with Parameter Instability, by Alexander Chudik, M. Hashem Pesaran and Mahrad Sharifvaghe, July 2020, revised April 2021
- Identifying the Effects of Sanctions on the Iranian Economy using Newspaper Coverage, by Dario Laudati and M. Hashem Pesaran, July 2021, Cambridge Working Papers in Economics, CWPE2155
- Climate Change and Economic Activity: Evidence from U.S. States, by Kamiar Mohaddes, Ryan N. C. Ng, M. Hashem Pesaran, Mehdi Raissi and Jui-Chung Yang, January 2022, Cambridge Working Papers in Economics, CWPE2205, CAMA Working Paper Series, vol 10/2022 and CESifo Working Paper No. 9542
- A Spatiotemporal Equilibrium Model of Migration and Housing Interlinkages, by Wukuang Cun and M. Hashem Pesaran. April 2018, revised September 2021
- A Bias-Corrected CD Test for Error Cross-Sectional Dependence in Panel Data Models with Latent Factors, by M. Hashem Pesaran and Yimeng Xie, July 2021, Cambridge Working Papers in Economics, CWPE2158
- Social Distancing, Vaccination and Evolution of COVID-19 Transmission Rates in Europe, by Alexander Chudik, M. Hashem Pesaran and Alessandro Rebucci, Cambridge Working Papers in Economics, CWPE2230, CESifo Working Paper No. 9754 May 2022
- Voluntary and Mandatory Social Distancing: Evidence on COVID-19 Exposure Rates from Chinese Provinces and Selected Countries, by Alexander Chudik, M. Hashem Pesaran and Alessandro Rebucci, CESifo Working Paper No. tbc, April 2020
- A Spatiotemporal Equilibrium Model of Migration and Housing Interlinkages, by Wukuang Cun and M. Hashem Pesaran, April 2022, Cambridge Working Papers in Economics, CWPE2225
- Matching Theory and Evidence on Covid-19 using a Stochastic Network SIR Model, by M. Hashem Pesaran and Cynthia Fan Yang, November 2020, revised September 2021
- Arbitrage Pricing Theory, the Stochastic Discount Factor and Estimation of Risk Premia from Portfolios, by M. Hashem Pesaran and Ron P. Smith, CESifo Working Paper No. 9001, July 2021, revised October 2021
- Arbitrage Pricing Theory, the Stochastic Discount Factor and Estimation of Risk Premia from Portfolios, by M. Hashem Pesaran and Ron P. Smith, CESifo Working Paper No. 9001, July 2021
- Long-Term Macroeconomic Effects of Climate Change: A Cross-Country Analysis, by Matthew E. Kahn, Kamiar Mohaddes, Ryan N. C. Ng, M. Hashem Pesaran, Mehdi Raissi and Jui-Chung Yang, CESifo Working Paper No. 7738, July 2019, revised September 2021
- Land Use Regulations, Migration and Rising House Price Dispersion in the U.S., by Wukuang Cun and M. Hashem Pesaran. April 2018, revised October 2018
- Matching Theory and Evidence on Covid-19 using a Stochastic Network SIR Model, by M. Hashem Pesaran and Cynthia Fan Yang, November 2020
- Long-Term Macroeconomic Effects of Climate Change: A Cross-Country Analysis, by Matthew E. Kahn, Kamiar Mohaddes, Ryan N. C. Ng, M. Hashem Pesaran, Mehdi Raissi and Jui-Chung Yang, CESifo Working Paper No. 7738, July 2019
- Measurement of Factor Strength: Theory and Practice, by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, forthcoming in Journal of Applied Econometrics, CESifo Working Paper No. tbc, January 2021
- A Counterfactual Economic Analysis of Covid-19 Using a Threshold Augmented Multi-Country Model, by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, Mehdi Raissi, and Alessandro Rebucci, September 2020, revised May 2021
- An Augmented Anderson-Hsiao Estimator for Dynamic Short-T Panels, by Alexander Chudik and M. Hashem Pesaran, CESifo WP no. 6688. October 2017, revised March 2021
- Short T Dynamic Panel Data Models with Individual, Time and Interactive Effects, by Kazuhiko Hayakawa, M. Hashem Pesaran and L. Vanessa Smith, September 2018, revised February 2020
- Regional Heterogeneity and U.S. Presidential Elections: Real-Time 2020 Forecasts and Evaluation, by Rashad Ahmed and M. Hashem Pesaran, October 2020, revised April 2021
- A Counterfactual Economic Analysis of Covid-19 Using a Threshold Augmented Multi-Country Model, by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, Mehdi Raissi, and Alessandro Rebucci, September 2020
- Variable Selection and Forecasting in High Dimensional Linear Regressions with Structural Breaks, by Alexander Chudik, M. Hashem Pesaran and Mahrad Sharifvaghe, July 2020
- A Bias-Corrected Method of Moments Approach to Estimation of Dynamic Short-T Panels, by Alexander Chudik and M. Hashem Pesaran, CESifo WP no. 6688. October 2017
- General Diagnostic Tests for Cross-sectional Dependence in Panels, by M. Hashem Pesaran, forthcoming in Empirical Economics, May 2020
- Estimation and Inference in Spatial Models with Dominant Units, by M. Hashem Pesaran and Cynthia Fan Yang, forthcoming in Journal of Econometrics, April 2020
- Detection of Units with Pervasive Effects in Large Panel Data Models", by George Kapetanios, M. Hashem Pesaran and Simon Reese, forthcoming in Journal of Econometrics, March 2020
- Estimation and Inference for Spatial Models with Heterogeneous Coefficients: An Application to U.S. House Prices, by Michele Aquaro, Natalia Bailey and M. Hashem Pesaran, forthcoming in Journal of Applied Econometrics, CESifo WP Series No. 7542. This paper was previously titled “Quasi-maximum likelihood estimation of spatial models with heterogeneous coefficient” (CESifo WP Series No. 5428)
- Econometric Analysis of Production Networks with Dominant Units, by M. Hashem Pesarann and Cynthia Fan Yang, USC Dornsife Working Paper No. 16-25, forthcoming in Journal of Econometrics, March 2019
- Measurement of Factor Strength: Theory and Practice, by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, CESifo Working Paper No. tbc, February 2020
- Identifying Global and National Output and Fiscal Policy Shocks Using a GVAR, by Alexander Chudik, M. Hashem Pesaran and Kamiar Mohaddes, December 2018
- Uncertainty and Economic Activity: A Multi-Country Perspective, by Ambrogio Cesa-Bianchi, M. Hashem Pesaran and Alessandro Rebucci, forthcoming in The Review of Financial Studies, June 2019
- Estimation and Inference in Spatial Models with Dominant Units, by M. Hashem Pesaran and Cynthia Fan Yang, March 2019, revised January 2020
- Estimation and Inference for Spatial Models with Heterogeneous Coefficients: An Application to U.S. House Prices, by Michele Aquaro, Natalia Bailey and M. Hashem Pesaran, CESifo WP Series No. 7542, March 2019, revised May 2020. This paper was previously titled “Quasi-maximum likelihood estimation of spatial models with heterogeneous coefficient” (CESifo WP Series No. 5428)
- Detection of Units with Pervasive Effects in Large Panel Data Models, by George Kapetanios, M. Hashem Pesaran and Simon Reese, CESifo WP no. 7401, November 2018, revised April 2019
- Estimation and inference for spatial models with heterogeneous coefficients: an application to U.S. house prices, by Michele Aquaro, Natalia Bailey and M. Hashem Pesaran, CESifo WP Series No. 7542, March 2019. This paper was previously titled “Quasi-maximum likelihood estimation of spatial models with heterogeneous coefficient” (CESifo WP Series No. 5428)
- Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Quantile Regression Models, by Matthew Harding, Carlos Lamarche and M. Hashem Pesaran, forthcoming in Journal of Applied Econometrics, December 2019
- Short T Dynamic Panel Data Models with Individual and Interactive Time Effects, by Kazuhiko Hayakawa, M. Hashem Pesaran and L. Vanessa Smith, September 2018
- Estimation and Inference in Spatial Models with Dominant Units, by M. Hashem Pesaran and Cynthia Fan Yang, March 2019
- Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Quantile Regression Models, by Matthew Harding, Carlos Lamarche and M. Hashem Pesaran. August 2018
- Exponent of Cross-sectional Dependence for Residuals, by Natalia Bailey, George Kapetanios and M. Hashem Pesaran. forthcoming in Sankhya B. The Indian Journal of Statistics, April 2019
- A Bayesian Analysis of Linear Regression Models with Highly Collinear Regressors, by M. Hashem Pesaran and Ron P. Smith, forthcoming in Econometrics and Statistics, October 2018
- Uncertainty and Economic Activity: A Multi-Country Perspective, by Ambrogio Cesa-Bianchi, M. Hashem Pesaran and Alessandro Rebucci. February 2018
- A Residual-based Threshold Method for Detection of Units that are Too Big to Fail in Large Factor Models, by George Kapetanios, M. Hashem Pesaran and Simon Reese, November 2018
- Mean Group Estimation in Presence of Weakly Cross-Correlated Estimators, by Alexander Chudik and M. Hashem Pesaran, forthcoming in Economics Letters, December 2018
- Exponent of Cross-sectional Dependence for Residuals, by Natalia Bailey, George Kapetanios and M. Hashem Pesaran. August 2018
- Quasi Maximum Likelihood Estimation of Spatial Models with Heterogeneous Coefficients, by Michele Aquaro, Natalia Bailey and M. Hashem Pesaran, CESifo WP Series No. 5428, June 2015
- Econometric Analysis of Production Networks with Dominant Units, by M. Hashem Pesarann and Cynthia Fan Yang, USC Dornsife Working Paper No. 16-25, October 2016, revised August 2017
- Mean Group Estimation in Presence of Weakly Cross-Correlated Estimators, by Alexander Chudik and M. Hashem Pesaran, November 2018
- Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes, by M. Hashem Pesarann and Ida Johnsson, forthcoming in Journal of Business and Economic Statistics, August 2018
- Half-Panel Jackknife Fixed Effects Estimation of Linear Panels with Weakly Exogenous Regressors, by Alexander Chudik, M. Hashem Pesarann and Jui-Chung Yang, SSRN Working Paper No. 281, forthcoming in Journal of Applied Econometrics, January 2018
- Tests of Policy Interventions in DSGE Models, by M. Hashem Pesaran and Ron P. Smith, forthcoming in Oxford Bulletin of Economics and Statistics, October 2017.
- A Multiple Testing Approach to the Regularisation of Large Sample Correlation Matrices, by Natalia Bailey, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.05, May 2014, revised September 2016
- Land Use Regulations, Migration and Rising House Price Dispersion in the U.S., by Wukuang Cun and M. Hashem Pesaran. April 2018
- Posterior Means and Precisions of the Coefficients in Linear Models with Highly Collinear Regressors, by M. Hashem Pesaran and Ron P. Smith. November 2017, revised August 2018
- Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes, by M. Hashem Pesarann and Ida Johnsson, forthcoming in Journal of Business and Economic Statistics, August 2018
- Transformed Maximum Likelihood Estimation of Short Dynamic Panel Data Models with Interactive Effects, by Kazuhiko Hayakawa, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.06, May 2014
- Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes, by M. Hashem Pesarann and Ida Johnsson, December 2016, revised June 2017
- Posterior Means and Precisions of the Coefficients in Linear Models with Highly Collinear Regressors, by M. Hashem Pesaran and Ron P. Smith. November 2017
- A One-Covariate at a Time, Multiple Testing Approach to Variable Selection in High-Dimensional Linear Regression Models, by Alexander Chudik, George Kapetanios and M. Hashem Pesaran, forthcoming in Econometrica, February 2018.
- Estimation of Time-invariant Effects in Static Panel Data Models, by M. Hashem Pesaran and Qiankun Zhou, forthcoming in Econometrics Reviews, June 2016.
- A One-Covariate at a Time, Multiple Testing Approach to Variable Selection in High-Dimensional Linear Regression Models, by Alexander Chudik, George Kapetanios and M. Hashem Pesaran, February 2016, revised November 2016
- To Pool or not to Pool: Revisited, by M. Hashem Pesaran and Qiankun Zhou, forthcoming in Oxford Bulletin of Economics and Statistics, October 2017
- Testing for Alpha in Linear Factor Pricing Models with a Large Number of Securities, by M. Hashem Pesarann and Takashi Yamagata, March 2017
- Half-Panel Jackknife Fixed Effects Estimation of Panels with Weakly Exogenous Regressors, by Alexander Chudik, M. Hashem Pesarann and Jui-Chung Yang, SSRN Working Paper No. 281, September 2016
- Counterfactual Analysis in Macroeconometrics: An Empirical Investigation into the Effects of Quantitative Easing, by M. Hashem Pesaran and Ron P Smith, IZA Discussion Paper No. 6618, May 2012, revised June 2014
- Oil Prices and the Global Economy: Is It Different This Time Around?, by Kamiar Mohaddes and M. Hashem Pesarann, July 2016
- Tests of Policy Ineffectiveness in Macroeconometrics, by M. Hashem Pesaran and Ron P. Smith, CAFE Research Paper No. 14.07, June 2014, revised January 2015
- To Pool or not to Pool: Revisited, by M. Hashem Pesaran and Qiankun Zhou, June 2015
- A multi-country approach to forecasting output growth using PMIs, by Alexander Chudik, Valerie Grossmanz and M. Hashem Pesaran, forthcoming in the Journal of Econometrics, January 2016.
- Is There a Debt-threshold Effect on Output Growth?, by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, and Mehdi Raissi, forthcoming in the Review of Economics and Statistics, November 2015.
- Exponent of Cross-sectional Dependence: Estimation and Inference, by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, forthcoming in the Journal of Applied Econometrics, January 2015.
- A Two Stage Approach to Spatio-Temporal Analysis with Strong and Weak Cross-Sectional Dependence, by Natalia Bailey, Sean Holly and M. Hashem Pesaran, CESifo Working Paper No. 4592, forthcoming in the Journal of Applied Econometrics, January 2015.
- Econometric Analysis of Production Networks with Dominant Units, by M. Hashem Pesarann and Cynthia Fan Yang, USC Dornsife Working Paper No. 16-25, October 2016
- An Exponential Class of Dynamic Binary Choice Panel Data Models with Fixed Effects, by Majid M. Al-Sadoon, Tong Li and M. Hashem Pesaran,CESifo Working Paper No. 4033, forthcoming in Econometrics Reviews, August 2016.
- Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes, by M. Hashem Pesarann and Ida Johnsson, December 2016, revised May 2017
- Oil Prices and the Global Economy: Is It Different This Time Around?, by Kamiar Mohaddes and M. Hashem Pesaran, July 2016
- Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes, by M. Hashem Pesaran and Ida Johnsson, December 2016, revised January 2017
- Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes, by M. Hashem Pesaran and Ida Johnsson, December 2016
- Big Data Analytics: A New Perspective, by Alexander Chudik, George Kapetanios and M. Hashem Pesaran, February 2016
- Country-Specific Oil Supply Shocks and the Global Economy: A Counterfactual Analysis, by Kamiar Mohaddes and M. Hashem Pesaran, forthcoming in Energy Economics, July 2016.
- Country-Specific Oil Supply Shocks and the Global Economy: A Counterfactual Analysis, by Kamiar Mohaddes and M. Hashem Pesaran, May 2015
- A Multiple Testing Approach to the Regularisation of Large Sample Correlation Matrices, by Natalia Bailey, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.05, May 2014, revised November 2015
- An Exponential Class of Dynamic Binary Choice Panel Data Models with Fixed Effects, by Majid M. Al-Sadoon, Tong Li and M. Hashem Pesaran,CESifo Working Paper No. 4033, October 2012, revised January 2016
- Estimation of Time-invariant Effects in Static Panel Data Models, by M. Hashem Pesaran and Qiankun Zhou, September 2014
- Long-Run Effects in Large Heterogenous Panel Data Models with Cross-Sectionally Correlated Errors, by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran and Mehdi Raissi, forthcoming in Advances in Econometrics, V36 Essays in Honor of Aman Ullah, 2016.
- Theory and Practice of GVAR Modeling, by Alexander Chudik, and M. Hashem Pesaran, SSRN Research Paper Series No. 14.04, forthcoming in the Journal of Economic Surveys, September 2014.
- Business Cycle Effects of Credit and Technology Shocks in a DSGE Model with Firm Default, by M. Hashem Pesaran and TengTeng Xu, CWPE Working paper. No. 1159, CESifo Working Paper No. 3609, IZA Discussion Paper No. 6027, October 2011, under revision
- An Exponential Class of Dynamic Binary Choice Panel Data Models with Fixed Effects", by Majid M. Al-Sadoon, Tong Li and M. Hashem Pesaran, CESifo Working Paper No. 4033, October 2012, revised August 2014
- Robust Standard Errors in Transformed Likelihood Estimation of Dynamic Panel Data Models with Cross-Sectional Heteroskedasticity, by Kazuhiko Hayakawa and M. Hashem Pesaran, CWPE Working Paper No. 1224, IZA Discussion Paper 6583, CESifo Working Paper No.3850, forthcoming in the Journal of Econometrics, March 2015.
- Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Data Models with Weakly Exogenous Regressors, by Alexander Chudik, and M. Hashem Pesaran, CESifo Working Paper No. 4232 and CAFE Research Paper No. 13.14, IZA Discussion Paper No. 6618, forthcoming in the Journal of Econometrics July 2014.
- Testing Weak Cross-Sectional Dependence in Large Panels, by M. Hashem Pesaran, CWPE Working Paper No. 1208, IZA Discussion Paper No. 6432, forthcoming in Econometric Reviews, January 2012.
- Debt, Inflation and Growth: Robust Estimation of Long-Run Effects in Dynamic Panel Data Models, by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, and Mehdi Raissi, November 2013
- A multi-country approach to forecasting output growth using PMIs, by Alexander Chudik, Valerie Grossmanz and M. Hashem Pesaran, November 2014
- Is There a Debt-threshold Effect on Output Growth?, by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, and Mehdi Raissi, July 2015
- A Multiple Testing Approach to the Regularisation of Large Sample Correlation Matrices, by Natalia Bailey, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.05, May 2014, revised January 2015
- Long-Run Effects in Large Heterogenous Panel Data Models with Cross-Sectionally Correlated Errors, by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran and Mehdi Raissi, January 2015
- Robust Standard Errors in Transformed Likelihood Estimation of Dynamic Panel Data Models with Cross-Sectional Heteroskedasticity, by Kazuhiko Hayakawa and M. Hashem Pesaran, CWPE Working Paper No. 1224, IZA Discussion Paper 6583, CESifo Working Paper No.3850, April 2012, revised January 2014
- Exponent of Cross-sectional Dependence: Estimation and Inference, by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, November 2013, revised December 2014
- A Multiple Testing Approach to the Regularisation of Large Sample Correlation Matrices, by Natalia Bailey, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.05, May 2014
- Constructing Multi-country Rational Expectations Models, by Stephane Dees, M. Hashem Pesaran, Ron P. Smith and L. Vanessa Smith, CESifo Working Papers No. 3081, October 2012, forthcoming in Oxford Bulletin of Economics and Statistics
- Large Panel Data Models with Cross-Sectional Dependence: A Survey, by Alexander Chudik, and M. Hashem Pesaran, CESifo Working Paper No. 4371, August 2013, forthcoming in B. H. Baltagi (Ed.), The Oxford Handbook on Panel Data. Oxford University Press.
- Tests of Policy Ineffectiveness in Macroeconometrics, by M. Hashem Pesaran and Ron P. Smith, CAFE Research Paper No. 14.07, June 2014
- A Two Stage Approach to Spatiotemporal Analysis with Strong and Weak Cross-Sectional Dependence", by Natalia Bailey, Sean Holly and M. Hashem Pesaran, December 2013, revised July 2014
- Exponent of Cross-sectional Dependence: Estimation and Inference, by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, November 2013
- Theory and Practice of GVAR Modeling, by Alexander Chudik, and M. Hashem Pesaran, SSRN Research Paper Series No. 14.04, May 2014
- An Exponential Class of Dynamic Binary Choice Panel Data Models with Fixed Effects, by Majid M. Al-Sadoon, Tong Li and M. Hashem Pesaran,CESifo Working Paper No. 4033, October 2012, revised December 2012
- A Two Stage Approach to Spatiotemporal Analysis with Strong and Weak Cross-Sectional Dependence", by Natalia Bailey, Sean Holly and M. Hashem Pesaran, December 2013
- Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Data Models with Weakly Exogenous Regressors, Alexander Chudik, and M. Hashem Pesaran, CESifo WP Number 4232, May 2013
- Counterfactual Analysis in Macroeconometrics: An Empirical Investigation into the Effects of Quantitative Easing, by M. Hashem Pesaran and Ron P Smith, IZA Discussion Paper No. 6618, May 2012, revised June 2012
- Optimal Forecasts in the Presence of Structural Breaks, by M. Hashem Pesaran, Andreas Pick and Mikhail Pranovich, (2013), forthcoming in Journal of Econometrics
- Signs of Impact Effects in Time Series Regression Models, by M. Hashem Pesaran and Ron P Smith, CESifo Working Paper, CAFE Research Paper No. 13.22, (2013), forthcoming in Economics Letters
- One Hundred Years of Oil Income and the Iranian Economy: A Curse or a Blessing?, by Kamiar Mohaddes, and M. Hashem Pesaran, CESifo Working Paper Series No. 4118, February 2013, forthcoming in Parvin Alizadeh and Hassan Hakimian (eds.), Iran and the Global Economy: Petro Populism, Islam and Economic Sanctions. Routledge, London.
- Panel Unit Root Test in the Presence of a Multifactor Error Structure", M. Hashem Pesaran, L. V. Smith, and T. Yamagata, December 2007. CWPE No. 0775, CESifo Working Papers, No. 2193, January 2008, IZA Discussion Paper No. 3254, December 2007. The University of York, Discussion Papers in Economics 08/03. Revised November 2012, forthcoming in Journal of Econometrics
- Testing CAPM with a Large Number of Assets, by M. Hashem Pesarann and Takashi Yamagata, February 2012
- An Empirical Growth Model for Major Oil Exporters, by Hadi Salehi Esfahani, Kamiar Mohaddes and M. Hashem Pesaran, (2012), forthcoming in Journal of Applied Econometrics
- Aggregation in Large Dynamic Panels, by M. Hashem Pesaran, Alexander Chudik, (2012), forthcoming in Journal of Econometrics
- Robust Standard Errors in Transformed Likelihood Estimation of Dynamic Panel Data Models, by Kazuhiko Hayakawa and M. Hashem Pesaran, CWPE Working Paper No. 1224, IZA Discussion Paper 6583, Cesifo Working Paper No.3850, April 2012, revised April 2012
- Signs of Impact Effects in Time Series Regression Models, by M. Hashem Pesaran and Ron P Smith, CESifo Working Paper, CAFE Research Paper No. 13.22 , October 2013
- Large Panel Data Models with Cross-Sectional Dependence: A Survey, by Alexander Chudik, and M. Hashem Pesaran, CESifo Working Paper No. 4371, August 2013
- One Hundred Years of Oil Income and the Iranian Economy: A Curse or a Blessing?, by Kamiar Mohaddes, and M. Hashem Pesaran, CESifo Working Paper Series No. 4118, December 2012, revised February 2013.
- Supply, Demand and Monetary Policy Shocks in a Multi-Country New Keynesian Model, by Stephane Dees, M. Hashem Pesaran, Ron P. Smith and L. Vanessa Smith, CESifo Working Papers No. 3081, June 2011, revised October 2012
- Counterfactual Analysis in Macroeconometrics: An Empirical Investigation into the Effects of Quantitative Easin, by M. Hashem Pesaran and Ron P Smith, May 2012
- One Hundred Years of Oil Income and the Iranian Economy: A Curse or a Blessing?, by Kamiar Mohaddes, and M. Hashem Pesaran, December 2012
- Testing Weak Cross-Sectional Dependence in Large Panels, by M. Hashem Pesaran, January 2012, Revised January 2013
- Econometric Analysis of High Dimensional VARs Featuring a Dominant Unit, by M. Hashem Pesaran and Alexander Chudik, (2011), forthcoming in the Econometrics Review.
- Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Data Models with Weakly Exogenous Regressors, by Alexander Chudik, and M. Hashem Pesaran, April 2013
- Panel Unit Root Test in the Presence of a Multifactor Error Structure, by M. Hashem Pesaran, L. Vanessa. Smith, and Takashi Yamagata, (2013), Forthcoming in Journal of Econometrics, Revised 2012
- A Panel Unit Root Test in the Presence of a Multifactor Error Structure, by M. Hashem Pesaran, L. Vanessa. Smith, and Takashi Yamagata December, 2007, Revised September 2009
- Business Cycle Effects of Credit and Technology Shocks in a DSGE Model with Firm Default, by M. Hashem Pesaran and TengTeng Xu, October 2011
- Optimal Forecasts in the Presence of Structural Breaks, by M. Hashem Pesaran, Andreas Pick and Mikhail Pranovich, October 2011, Revised December 2011
- On Identification of Bayesian DSGE Models, by Gary Koop, M. Hashem Pesaran and Ron P. Smith, March 2011, Revised August 2012
- Testing Weak Cross-Sectional Dependence in Large Panels, by M. Hashem Pesaran, January 2012
- On Identification of Bayesian DSGE Models, by Gary Koop, M. Hashem Pesaran and Ron P. Smith, March 2011, Revised September 2011
- Oil Exports and the Iranian Economy, by Hadi Salehi Esfahani, Kamiar Mohaddes and M. Hashem Pesaran, April 2012
- Oil Exports and the Iranian Economy, by Hadi Salehi Esfahani, Kamiar Mohaddes, and M. Hashem Pesaran, October, 2009
- On the Interpretation of Panel Unit Root Tests, by M. Hashem Pesaran, September 2011
- Aggregation in Large Dynamic Panels, by M. Hashem Pesaran, Alexander Chudik, January 2011, Revised November 2011
- Beyond the DSGE Straitjacket, by M. Hashem Pesaran and Ron P. Smith, May 2011
- China's Emergence in the World Economy and Business Cycles in Latin America, by Ambrogio Cesa-Bianchi, M. Hashem Pesaran, Alessandro Rebucci and TengTeng Xu, July 2011
- Beyond the DSGE straitjacket, by M. Hashem Pesaran and Ron P. Smith, April 2011
- Econometric Analysis of High Dimensional VARs Featuring a Dominant Unit, by M. Hashem Pesaran and Alexander Chudik, March, 2010
- Supply, Demand and Monetary Policy Shocks in a Multi-Country New Keynesian Model, by Stephane Dees, M. Hashem Pesaran, L. Vanessa Smith and Ron P. Smith, May 2010
- Diagnostic Tests of Cross Section Independence for Nonlinear Panel Data Models, by Cheng Hsiao, M. Hashem Pesaran and Andreas Pick April, 2007, Revised July 2010
- Lumpy Price Adjustments: A Microeconometric Analysis, Emmanuel Dhyney, Catherine Fuss, M. Hashem Pesaran, Patrick Sevestre April, 2007, Revised August 2008
- Large Panels with Common Factors and Spatial Correlation, M. Hashem Pesaran and Elisa Tosetti August, 2007, Revised May 2010
- Variable Selection, Estimation and Inference for Multi-period Forecasting Problems, by M. Hashem Pesaran, A. Pick and A. Timmerman April, 2010
- Panels with Nonstationary Multifactor Error Structures , by G. Kapetanios, M. Hashem Pesaran and T. Yamagata July, 2006, Revised June 2009
- Spatial and Temporal Diffusion of House Prices in the UK, by Sean Holly, M. Hashem Pesaran and Takashi Yamagata December, 2009
- Predictability of Asset Returns and the Efficient Market Hypothesis, by M. Hashem Pesaran May 2010
- Weak and Strong Cross Section Dependence and Estimation of Large Panels, by Alexander Chudik, M. Hashem Pesaran and Elisa Tosetti, April, 2010
- Infinite Dimensional VARs and Factor Models, Alexander Chudik and M. Hashem Pesaran November, 2007, revised January 2010
- Forecasting Random Walks Under Drift Instability, by M. Hashem Pesaran and Andreas Pick, March, 2008, Revised January 2009
- A VECX* Model of the Swiss Economy, by Katrin Assenmacher-Wesche and M. Hashem Pesaran February, 2008
- Modelling Volatilities and Conditional Correlations in Futures Markets with a Multivariate t Distribution, Bahram Pesaran and M. Hashem Pesaran June, 2007
-
"Forecasting with Panel Data: Estimation Uncertainty Versus Parameter Heterogeneity", by M. Hashem Pesaran, Andreas Pick and Allan Timmermann, March 2022, Cambridge Working Papers in Economics, CWPE2219
Abstract: We develop novel forecasting methods for panel data with heterogeneous parameters and examine them together with existing approaches. We conduct a systematic comparison of their predictive accuracy in settings with different cross-sectional (N) and time (T) dimensions and varying degrees of parameter heterogeneity. We investigate conditions under which panel forecasting methods can perform better than forecasts based on individual estimates and demonstrate how gains in predictive accuracy depend on the degree of parameter heterogeneity, whether heterogeneity is correlated with the regressors, the goodness of fit of the model, and, particularly, the time dimension of the data set. We propose optimal combination weights for forecasts based on pooled and individual estimates and develop a novel forecast poolability test that can be used as a pretesting tool. Through a set of Monte Carlo simulations and three empirical applications to house prices, CPI inflation, and stock returns, we show that no single forecasting approach dominates uniformly. However, forecast combination and shrinkage methods provide better overall forecasting performance and offer more attractive risk profiles compared to individual, pooled, and random effects methods.
JEL Classifications: C33, C53
Key Words: Forecasting, Panel data, Heterogeneity, Forecast evaluation, Forecast combination, Shrinkage, Pooling
Full Text: https://www.econ.cam.ac.uk/research-files/repec/cam/pdf/cwpe2219.pdf
-
"High-Dimensional Forecasting with Known Knowns and Known Unknowns", by M. Hashem Pesaran and Ron P. Smith, February 2024, Cambridge Working Papers in Economics, CWPE2406
Abstract: Forecasts play a central role in decision making under uncertainty. After a brief review of the general issues, this paper considers ways of using high-dimensional data in forecasting. We consider selecting variables from a known active set, known knowns, using Lasso and OCMT, and approximating unobserved latent factors, known unknowns, by various means. This combines both sparse and dense approaches. We demonstrate the various issues involved in variable selection in a high-dimensional setting with an application to forecasting UK inflation at different horizons over the period 2020q1-2023q1. This application shows both the power of parsimonious models and the importance of allowing for global variables.
JEL Classifications: C53, C55, E37, E52
Key Words: Forecasting, high-dimensional data, Lasso, OCMT, latent factors, principal components
Full Text: https://doi.org/10.17863/CAM.107469
arXiv link: https://arxiv.org/abs/2401.14582
-
"Pooled Bewley Estimator of Long Run Relationships in Dynamic Heterogenous Panels", by Alexander Chudik, M. Hashem Pesaran, and Ron P. Smith, May 2021.
Abstract: This paper, using the Bewley (1979) transformation of the autoregressive distributed lag model, proposes a pooled Bewley (PB) estimator of long-run coefficients for dynamic panels with heterogeneous short-run dynamics, in the same setting as the widely used Pooled Mean Group (PMG) estimator. The Bewley transform enables us to obtain an analytical closed form expression for the PB, which is not available when using the maximum likelihood approach. This lets us establish asymptotic normality of PB as n, T → ∞ jointly, allowing for applications with n and T large and of the same order of magnitude, but excluding panels where T is short relative to n. In contrast, asymptotic distribution of PMG estimator was obtained for n fixed and T → ∞. Allowing for both n and T large seems to be the more relevant empirical setting, as revealed by numerous applications of the PMG estimator in the literature. Dynamic panel estimators are biased when T is not sufficiently large. Three bias corrections (simulation based, split-panel jackknife, and a combined procedure) are investigated using Monte Carlo experiments, of which the combined procedure works best in reducing bias. In contrast to PMG, PB does not weight by estimated variances, which can make it more robust in small samples, though less efficient asymptotically. The PB estimator is illustrated with an application to the aggregate consumption function estimated in the original PMG paper.
JEL Classifications: C12, C13, C23, C33
Key Words: Heterogeneous dynamic panels; I(1) regressors; pooled mean group estimator (PMG), Autoregressive-Distributed Lag model (ARDL), Bewley transform, bias correction, split-panel jackknife.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/PB_2021May27_paper_with_supplement.pdf
Codes and Data: /people-files/emeritus/mhp1/wp21/PB_codes_and_data.zip
-
"Causal Effects of the Fed's Large-Scale Asset Purchases on Firms' Capital Structure", by Andrea Nocera and M. Hashem Pesaran, April 2022, Cambridge Working Papers in Economics, CWPE2224
Abstract: This paper investigates the short- and long-term impacts of the Federal Reserve’s large-scale asset purchases (LSAPs) on the capital structure of U.S. non-financial firms. To isolate the effects of LSAPs from the impact of concurrent macroeconomic conditions, we exploit cross-industry variations in the ability of firms therein to raise external funds without exhausting their debt capacity. We show that firms’ responses to LSAPs strongly depend on the financing decisions of other peers in the same industry. The higher the proportion of firms without high debt burdens in an industry, the stronger the response of firms within the industry to the Fed’s asset purchases. Overall, our results show that LSAPs facilitated firms’ access to debt financing and that the impacts of LSAPs on firms’ capital structure are likely to be long-lasting.
JEL Classifications: G32, E44, E52, E58
Key Words: Capital structure, identification, interactive effects, leverage, quantitative easing, unconventional monetary policy
Full Text: https://www.econ.cam.ac.uk/research-files/repec/cam/pdf/cwpe2224.pdf
-
"Revisiting the Great Ratios Hypothesis", by Alexander Chudik, M. Hashem Pesaran and Ron P. Smith, March 2022, Cambridge Working Papers in Economics, CWPE2215 and CESifo Working Paper No. 9625
Abstract: The idea that certain economic variables are roughly constant in the long-run is an old one. Kaldor described them as stylized facts, whereas Klein and Kosobud labelled them great ratios. While such ratios are widely adopted in theoretical models in economics as conditions for balanced growth, arbitrage or solvency, the empirical literature has tended to find little evidence for them. We argue that this outcome could be due to episodic failure of cointegration, possible two-way causality between the variables in the ratios, and cross-country error dependence due to latent factors. We propose a new system pooled mean group estimator (SPMG) to deal with these features. Using this new panel estimator and a dataset spanning almost one and half centuries and seventeen countries, we find support for five out of the seven great ratios that we consider. Extensive Monte Carlo experiments also show that the SPMG estimator with bootstrapped confidence intervals stands out as the only estimator with satisfactory small sample properties.
JEL Classifications: B40, C18, C33, C50
Key Words: Great ratios, debt, consumption, and investment to GDP ratios, arbitrage conditions, heterogeneous panels, episodic cointegration, two-way long-run causality, error cross-sectional dependence
Full Text: https://www.econ.cam.ac.uk/research-files/repec/cam/pdf/cwpe2215.pdf
CESifo: https://www.cesifo.org/en/publikationen/2022/working-paper/revisiting-great-ratios-hypothesis
-
"Short T Dynamic Panel Data Models with Individual, Time and Interactive Effects", by Kazuhiko Hayakawa, M. Hashem Pesaran and L. Vanessa Smith, September 2018, revised July 2021
Abstract: This paper proposes a transformed quasi maximum likelihood (TQML) estimator for short T dynamic fixed effects panel data models allowing for interactive effects through a multi-factor error structure. The proposed estimator is robust to the heterogeneity of the initial values and common unobserved effects, whilst at the same time allowing for standard fixed and time effects. It is applicable to both stationary and unit root cases. The order condition for identification of the number of interactive effects is established, and conditions are derived under which the parameters are almost surely locally identified. It is shown that global identification in the presence of the lagged dependent variable cannot be guaranteed. The TQML estimator is proven to be consistent and asymptotically normally distributed. A sequential multiple testing likelihood ratio procedure is also proposed for estimation of the number of factors which is shown to be consistent. Finite sample results obtained from Monte Carlo simulations show that the proposed procedure for determining the number of factors performs very well and the TQML estimator has small bias and RMSE, and correct empirical size in most settings. The practical use of the TQML approach is demonstrated by means of two empirical illustrations from the literature on cross county crime rates and cross country growth regressions.
JEL Classifications: C12, C13, C23.
Key Words: short T dynamic panels, unobserved common factors, quasi maximum likelihood, interactive effects, multiple testing, sequential likelihood ratio tests, crime rate, growth regressions.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/Short_Panel_with_interactive_effects_HPS_25July21.pdf
SSRN Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3268434
-
"Factor Strengths, Pricing Errors, and Estimation of Risk Premia", by M. Hashem Pesaran and Ron P. Smith, March 2021, CESifo Working Paper No. 8947.
Abstract: This paper examines the implications of pricing errors and factors that are not strong for the Fama-MacBeth two-pass estimator of risk premia and its asymptotic distribution when T is fixed with n → ∞, and when both n and T → ∞, jointly. While the literature just distinguishes strong and weak factors we allow for degrees of strength using a recently developed measure. Our theoretical results have important practical implications for empirical asset pricing. Pricing errors and factor strength matter for consistent estimation of risk premia and subsequent inference, thus an estimate of factor strength is required before attempting to estimate risk. Finally, using a recently developed procedure we provide rolling estimates of factor strengths for the five Fama-French factors, and show that only the market factor can be viewed as strong.
JEL Classifications: C380, G120
Key Words: factor strength, pricing errors, risk premia, Fama and MacBeth two-pass estimators, Fama-French factors, panel R2.
Full Text: https://www.cesifo.org/en/publikationen/2021/working-paper/factor-strengths-pricing-errors-and-estimation-risk-premia
-
"COVID-19 Time-varying Reproduction Numbers Worldwide: An Empirical Analysis of Mandatory and Voluntary Social Distancing", by Alexander Chudik, M. Hashem Pesaran and Alessandro Rebucci, March 2021.
Abstract: This paper estimates time-varying COVID-19 reproduction numbers worldwide solely based on the number of reported infected cases, allowing for under-reporting. Estimation is based on a moment condition that can be derived from an agent-based stochastic network model of COVID-19 transmission. The outcomes in terms of the reproduction number and the trajectory of per-capita cases through the end of 2020 are very diverse. The reproduction number depends on the transmission rate and the proportion of susceptible population, or the herd immunity effect. Changes in the transmission rate depend on changes in the behavior of the virus, reflecting mutations and vaccinations, and changes in people's behavior, reflecting voluntary or government mandated isolation. Over our sample period, neither mutation nor vaccination are major factors, so one can attribute variation in the transmission rate to variations in behavior. Evidence based on panel data models explaining transmission rates for nine European countries indicates that the diversity of outcomes resulted from the non-linear interaction of mandatory containment measures, voluntary precautionary isolation, and the economic incentives that governments provided to support isolation. These effects are precisely estimated and robust to various assumptions. As a result, countries with seemingly different social distancing policies achieved quite similar outcomes in terms of the reproduction number. These results imply that ignoring the voluntary component of social distancing could introduce an upward bias in the estimates of the effects of lock-downs and support policies on the transmission rates.
JEL Classifications: D0, F6, C4, I120, E7
Key Words: COVID-19, SIR model, epidemics, multiplication factor, under-reporting, social distancing, self-isolation.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/CPR_covid_2021_Mar_15_WP.pdf
Public Codes: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/codes.zip
-
"Identification and Estimation of Categorical Random Coeficient Models", by Zhan Gao and M. Hashem Pesaran, April 2022, Cambridge Working Papers in Economics, CWPE2228
Abstract: This paper proposes a linear categorical random coefficient model, in which the random coefficients follow parametric categorical distributions. The distributional parameters are identified based on a linear recurrence structure of moments of the random coefficients. A Generalized Method of Moments estimator is proposed, and its finite sample properties are examined using Monte Carlo simulations. The utility of the proposed method is illustrated by estimating the distribution of returns to education in the U.S. by gender and educational levels. We find that rising heterogeneity between educational groups is mainly due to the increasing returns to education for those with postsecondary education, whereas within group heterogeneity has been rising mostly in the case of individuals with high school or less education.
JEL Classifications: C01, C21, C13, C46, J30
Key Words: Random coefficient models, categorical distribution, return to education
Full Text: https://www.econ.cam.ac.uk/research-files/repec/cam/pdf/cwpe2228.pdf
-
"Testing for Alpha in Linear Factor Pricing Models with a Large Number of Securities", by M. Hashem Pesaran and Takashi Yamagata, March 2017, revised January 2018
Abstract: This paper considers tests of zero pricing errors for the linear factor pricing model when the number of securities, N, can be large relative to the time dimension, T, of the return series. We focus on class of tests that are based on Student t tests of individual securities which have a number of advantages over the existing standardised Wald type tests, and propose a test procedure that allows for non-Gaussianity and general forms of weakly cross correlated errors. It does not require estimation of an invertible error covariance matrix, it is much faster to implement, and is valid even if N is much larger than T. Monte Carlo evidence shows that the proposed test performs remarkably well even when T = 60 and N = 5; 000. The test is applied to monthly returns on securities in the S&P 500 at the end of each month in real time, using rolling windows of size 60. Statistically signifi cant evidence against Sharpe-Lintner CAPM and Fama-French three factor models are found mainly during the recent fi nancial crisis. Also we fi nd a signifi cant negative correlation between a twelve-months moving average p-values of the test and excess returns of long/short equity strategies (relative to the return on S&P 500) over the period November 1994 to June 2015, suggesting that abnormal pro ts are earned during episodes of market ineffiencies.
JEL Classifications: C12, C15, C23, G11, G12
Key Words: CAPM, Testing for alpha, Weak and spatial error cross-sectional dependence, S&P 500 securities, Long/short equity strategy.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/PY_LFPM_30_Jan_2018.pdf
Supplement: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/PY_LFPM_11_March_2017_Supplement.pdf
-
"Reflections on "Testing for Unit Roots in Heterogeneous Panels"", by Kyung So Im, M. Hashem Pesaran and Yongcheol Shin, January 2023, Cambridge Working Papers in Economics, CWPE2310
Abstract: This article is our personal perspective on the IPS test and the subsequent developments of unit root and cointegration tests in dynamic panels with and without cross-section dependence. In this note, we discuss the main idea behind the test and the publication process that led to Im, Pesaran and Shin (2003).
JEL Classifications: C01, C23
Key Words: Dickey and Fuller statistic, stationarity, panel unit root tests, prevalence of unit roots
Full Text: https://www.econ.cam.ac.uk/research-files/repec/cam/pdf/cwpe2310.pdf
-
"Variable Selection and Forecasting in High Dimensional Linear Regressions with Parameter Instability", by Alexander Chudik, M. Hashem Pesaran and Mahrad Sharifvaghe, July 2020, revised April 2021.
Abstract: This paper is concerned with the problem of variable selection and forecasting in the presence of parameter instability. There are a number of approaches proposed for forecasting in the presence of time-varying parameters, including the use of rolling windows and exponential down-weighting. However, these studies start with a given model specification and do not consider the problem of variable selection, which is complicated by time variations in the effects of signals on target variables. In this study we investigate whether or not we should use weighted observations at the variable selection stage in the presence of parameter instability, particularly when the number of potential covariates is large. Amongst the extant variable selection approaches we focus on the recently developed One Covariate at a time Multiple Testing (OCMT) method. This procedure allows a natural distinction between the selection and forecasting stages. We establish three main theorems on selection, estimation post selection, and in-sample fit. These theorems provide justification for using the full (not down-weighted) sample at the selection stage of OCMT and down-weighting of observations only at the forecasting stage (if needed). The benefits of the proposed method are illustrated by empirical applications to forecasting monthly stock market returns and quarterly output growths.
JEL Classifications: C22, C52, C53, C55
Key Words: Time-varying parameters, high-dimensional, multiple testing, variable selection, Lasso, one covariate at a time multiple testing (OCMT), forecasting, monthly returns, Dow Jones
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/CPS_OCMT_Break_Forecatsing_04_23_2021f.pdf
-
"Identifying the Effects of Sanctions on the Iranian Economy using Newspaper Coverage", by Dario Laudati and M. Hashem Pesaran, July 2021, Cambridge Working Papers in Economics, CWPE2155.
Abstract: This paper considers how sanctions affected the Iranian economy using a novel measure of sanctions intensity based on daily newspaper coverage. It finds sanctions to have significant effects on exchange rates, inflation, and output growth, with the Iranian rial over-reacting to sanctions, followed up with a rise in inflation and a fall in output. In absence of sanctions, Iran’s average annual growth could have been around 4-5 per cent, as compared to the 3 per cent realized. Sanctions are also found to have adverse effects on employment, labor force participation, secondary and high-school education, with such effects amplified for females.
JEL Classifications: E31, E65, F43, F51, F53, O11, O19, O53
Key Words: Newspaper coverage, identification of direct and indirect effects of sanctions, Iran output growth, exchange rate depreciation and inflation, labor force participation and employment, secondary education, and gender bias.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/LP_Iran_Sanctions_July_27_2021(paper_&_supplement).pdf
Data and Codes: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/LP_Iran_sanctions-Replication_files_(Aug_2021).zip
-
"Climate Change and Economic Activity: Evidence from U.S. States", by Kamiar Mohaddes, Ryan N. C. Ng, M. Hashem Pesaran, Mehdi Raissi and Jui-Chung Yang, January 2022, Cambridge Working Papers in Economics, CWPE2205, CAMA Working Paper Series, vol 10/2022 and CESifo Working Paper No. 9542
Abstract: We investigate the long-term macroeconomic effects of climate change across 48 U.S. states over the period 1963 2016 using a novel econometric strategy which links deviations of temperature and precipitation (weather) from their long-term moving-average historical norms (climate) to various state-specific economic performance indicators at the aggregate and sectoral levels. We show that climate change has a long-lasting adverse impact on real output in various states and economic sectors, and on labour productivity and employment in the United States. Moreover, in contrast to most cross-country results, our within U.S. estimates tend to be asymmetrical with respect to deviations of climate variables (including precipitation) from their historical norms.
JEL Classifications: C33, O40, O44, O51, Q51, Q54
Key Words: Adaptation, Climate Change, economic growth, United States
Full Text: https://www.econ.cam.ac.uk/research-files/repec/cam/pdf/cwpe2205.pdf
CAMA: https://cama.crawford.anu.edu.au/publication/cama-working-paper-series/19864/climate-change-and-economic-activity-evidence-us-states
CESifo: https://www.cesifo.org/en/publikationen/2022/working-paper/climate-change-and-economic-activity-evidence-us-states
-
"A Spatiotemporal Equilibrium Model of Migration and Housing Interlinkages", by Wukuang Cun and M. Hashem Pesaran. April 2018, revised September 2021
Abstract: This paper develops and solves a spatiotemporal equilibrium model in which regional wages and house prices are determined jointly with location-to-location migration flows. The agent's optimal location choice and the resultant migration process are shown to be Markovian, with the transition probabilities across all location pairs given as non-linear functions of wage and housing cost differentials, endogenously responding to migration flows. The model can be used for the analysis of spatial distribution of population, income, and house prices, as well as for the analysis of the entire dynamic process of shock spill-over effects in regional economies through location-to-location migration. The model is estimated on a panel of 48 mainland U.S. states and the District of Columbia over the training sample (1976-1999) and is shown to fit the data well over the evaluation sample (2000-2014). The estimated model is then used to analyze the size and speed of spatial spill-over effects by computing spatiotemporal impulse responses of positive productivity and land-supply shocks to California, Texas, and Florida. The sensitivity of the results to migration elasticity, housing depreciation rate and local land supply conditions is also investigated.
JEL Classifications: E0, R23, R31
Key Words: location choice, joint determination of migration and house prices, spatiotemporal impulse responses, land-use deregulation, counterfactual exercise, population allocation, productivity and land supply shocks, California, Texas and Florida.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/PC_Housing_Paper_2021_09_30.pdf
SSRN Working Paper Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3162399
-
"A Bias-Corrected CD Test for Error Cross-Sectional Dependence in Panel Data Models with Latent Factors", by M. Hashem Pesaran and Yimeng Xie, July 2021, Cambridge Working Papers in Economics, CWPE2158.
Abstract: In a recent paper Juodis and Reese (2021) (JR) show that the application of the CD test proposed by Pesaran (2004) to residuals from panels with latent factors results in over-rejection and propose a randomized test statistic to correct for over-rejection, and add a screening component to achieve power. This paper considers the same problem but from a different perspective and shows that the standard CD test remains valid if the latent factors are weak, and proposes a simple bias-corrected CD test, labelled CD*, which is shown to be asymptotically normal, irrespective of whether the latent factors are weak or strong. This result is shown to hold for pure latent factor models as well as for panel regressions with latent factors. Small sample properties of the CD* test are investigated by Monte Carlo experiments and are shown to have the correct size and satisfactory power for both Gaussian and non-Gaussian errors. In contrast, it is found that JR's test tends to over-reject in the case of panels with non-Gaussian errors, and have low power against spatial network alternatives. The use of the CD* test is illustrated with two empirical applications from the literature.
JEL Classifications: C18, C23, C55
Key Words: Latent factor models, strong and weak factors, error cross-sectional dependence, spatial and network alternatives.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/Pesaran-Xie Bias-corrected_CD_test_July_31_2021_(YX 081721).pdf
Data and Codes: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/codes_and_data_for_bias-corrected_CD_test.zip
-
"Social Distancing, Vaccination and Evolution of COVID-19 Transmission Rates in Europe", by Alexander Chudik, M. Hashem Pesaran and Alessandro Rebucci, Cambridge Working Papers in Economics, CWPE2230, CESifo Working Paper No. 9754 May 2022.
Abstract: This paper provides estimates of COVID-19 effective reproduction numbers and explains their evolution for selected European countries since the start of the pandemic taking account of changes in voluntary and government mandated social distancing, incentives to comply, vaccination and the emergence of new variants. Evidence based on panel data modeling indicates that the diversity of outcomes that we document may have resulted from the non-linear interaction of mandated and voluntary social distancing and the economic incentives that governments provided to support isolation. The importance of these factors declined over time, with vaccine uptake driving heterogeneity in country experiences in 2021. Our approach, also allows us to identify the basic reproduction number, R0. It is precisely estimated and differ little across countries.
JEL Classifications: D0, F6, C4, I120, E7
Key Words: COVID-19, multiplication factor, under-reporting, social distancing, self-isolation, SIR model, reproduction number, pandemics, vaccine.
Full Text: https://www.econ.cam.ac.uk/research-files/repec/cam/pdf/cwpe2230.pdf
CESifo: https://www.cesifo.org/en/publikationen/2022/working-paper/social-distancing-vaccination-and-evolution-covid-19-transmission
-
"Voluntary and Mandatory Social Distancing: Evidence on COVID-19 Exposure Rates from Chinese Provinces and Selected Countries", by Alexander Chudik, M. Hashem Pesaran and Alessandro Rebucci, CESifo Working Paper No. tbc, April 2020.
Abstract: This paper estimates time-varying COVID-19 reproduction numbers worldwide solely based on the number of reported infected cases, allowing for under-reporting. Estimation is based on a moment condition that can be derived from an agent-based stochastic network model of COVID-19 transmission. The outcomes in terms of the reproduction number and the trajectory of per-capita cases through the end of 2020 are very diverse. The reproduction number depends on the transmission rate and the proportion of susceptible population, or the herd immunity effect. Changes in the transmission rate depend on changes in the behavior of the virus, reflecting mutations and vaccinations, and changes in people's behavior, reflecting voluntary or government mandated isolation. Over our sample period, neither mutation nor vaccination are major factors, so one can attribute variation in the transmission rate to variations in behavior. Evidence based on panel data models explaining transmission rates for nine European countries indicates that the diversity of outcomes results from the non-linear interaction of mandatory containment measures, voluntary precautionary isolation, and the economic incentives that governments provided to support isolation. These effects are precisely estimated and robust to various assumptions. As a result, countries with seemingly different social distancing policies achieved quite similar outcomes in terms of the reproduction number. These results imply that ignoring the voluntary component of social distancing could introduce an upward bias in the estimates of the effects of lock-downs and support policies on the transmission rates. The full set of estimation results and the replication package are available on the authors' websites.
JEL Classifications: D0, F6, C4, I120, E7
Key Words: COVID-19, SIR model, epidemics, exposed population, measurement error, social distancing, self-isolation, employment loss.
Full Text: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3576703
-
"A Spatiotemporal Equilibrium Model of Migration and Housing Interlinkages", by Wukuang Cun and M. Hashem Pesaran, April 2022, Cambridge Working Papers in Economics, CWPE2225
Abstract: This paper develops and solves a spatiotemporal equilibrium model in which regional wages and house prices are jointly determined with location-to-location migration flows. The agent’s optimal location choice and the resultant migration process are shown to be Markovian, with the transition probabilities across all location pairs given as non-linear functions of wage and housing cost differentials, endogenously responding to migration flows. The model can be used for the analysis of spatial distribution of population, income, and house prices, as well as for spatiotemporal impulse response analysis. The model is estimated on a panel of 48 mainland U.S. states and the District of Columbia using the training sample (1976-1999), and shown to fit the data well over the evaluation sample (2000-2014). The estimated model is then used to analyze the size and speed of spatial spill-over effects by computing spatiotemporal impulse responses of positive productivity and land-supply shocks to California, Texas, and Florida. Our simulation results show that states with a lower level of land-use regulation can benefit more from positive state-specific productivity shocks; and positive land-supply shocks are much more effective in states, such as California, that are subject to more stringent land-use regulations.
JEL Classifications: E00, R23, R31
Key Words: location choice, joint determination of migration flows and house prices, spatiotemporal impulse response analysis, land-use deregulation, population allocation, productivity and land supply shocks, California, Texas and Florida
Full Text: https://www.econ.cam.ac.uk/research-files/repec/cam/pdf/cwpe2225.pdf
-
"Matching Theory and Evidence on Covid-19 using a Stochastic Network SIR Model", by M. Hashem Pesaran and Cynthia Fan Yang, November 2020, revised September 2021.
Abstract: This paper develops an individual-based stochastic network SIR model for the empirical analysis of the Covid-19 pandemic. It derives moment conditions for the number of infected and active cases for single as well as multigroup epidemic models. These moment conditions are used to investigate the identification and estimation of the transmission rates. The paper then proposes a method that jointly estimates the transmission rate and the magnitude of under-reporting of infected cases. Empirical evidence on six European countries matches the simulated outcomes once the under-reporting of infected cases is addressed. It is estimated that the number of actual cases could be between 4 to 10 times higher than the reported numbers in October 2020 and declined to 2 to 3 times in April 2021. The calibrated models are used in the counterfactual analyses of the impact of social distancing and vaccination on the epidemic evolution, and the timing of early interventions in the UK and Germany.
JEL Classifications: C13, C15, C31, D85, I18, J18
Key Words: Covid-19, multigroup SIR model, basic and effective reproduction numbers, transmission rates, vaccination, calibration and counterfactual analysis.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/PY_epidemic_network_Sep_1_2021.pdf
Replication Files: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/PY_epidemic_network_replication_files_Sep_2021.zip
Readme File: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/README.txt
arXiv.org Link: https://arxiv.org/abs/2109.00321
-
"Arbitrage Pricing Theory, the Stochastic Discount Factor and Estimation of Risk Premia from Portfolios", by M. Hashem Pesaran and Ron P. Smith, CESifo Working Paper No. 9001, July 2021, revised October 2021.
Abstract: The arbitrage pricing theory (APT) attributes differences in expected returns to exposure to systematic risk factors. Two aspects of the APT are considered. Firstly, the factors in the statistical asset pricing model are related to a theoretically consistent set of factors defined by their conditional covariation with the stochastic discount factor (SDF) used to price securities within inter-temporal asset pricing models. It is shown that risk premia arise from non-zero correlation of observed factors with SDF and the pricing errors arise from the correlation of the errors in the statistical model with SDF. Secondly, the estimates of factor risk premia using portfolios are compared to those obtained using individual securities. It is shown that in the presence of pricing errors consistent estimation of risk premia requires a large number of not fully diversified portfolios. Also, in general, it is not possible to rank estimators using individual securities and portfolios in terms of their small sample bias.
JEL Classifications: C38, G12
Key Words: Arbitrage Pricing Theory, Stochastic Discount Factor, portfolios, factor strength, identification of risk premia, two-pass regressions, Fama-MacBeth.
Full Text: https://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/PS_WP_revised_Portfolios_7_October_2021.pdf
CESifo Full Text: https://www.cesifo.org/node/62812
-
"Arbitrage Pricing Theory, the Stochastic Discount Factor and Estimation of Risk Premia from Portfolios", by M. Hashem Pesaran and Ron P. Smith, CESifo Working Paper No. 9001, July 2021.
Abstract: The arbitrage pricing theory (APT) attributes differences in expected returns to exposure to systematic risk factors, which are typically assumed to be strong. In this paper we consider two aspects of the APT. Firstly we relate the factors in the statistical factor model to a theoretically consistent set of factors defined by their conditional covariation with the stochastic discount factor (mt) used to price securities within inter-temporal asset pricing models. We show that risk premia arise from non-zero correlation of observed factors with mt; and the pricing errors arise from the correlation of the errors in the statistical factor model with mt: Secondly we compare estimates of factor risk premia using portfolios with the ones obtained using individual securities, and show that the identification conditions in terms of the strength of the factor are the same and that, in general, no clear cut ranking of the small sample bias of the two estimators is possible.
JEL Classifications: C38, G12
Key Words: Arbitrage Pricing Theory, Stochastic Discount Factor, portfolios, factor strength, identification of risk premia, two-pass regressions, Fama-MacBeth.
Full Text: https://www.cesifo.org/en/publikationen/2021/working-paper/arbitrage-pricing-theory-stochastic-discount-factor-and-estimation
-
"Long-Term Macroeconomic Effects of Climate Change: A Cross-Country Analysis", by Matthew E. Kahn, Kamiar Mohaddes, Ryan N. C. Ng, M. Hashem Pesaran, Mehdi Raissi and Jui-Chung Yang, CESifo Working Paper No. 7738, July 2019, revised September 2021.
Abstract: We study the long-term impact of climate change on economic activity across countries, using a stochastic growth model where productivity is affected by deviations of temperature and precipitation from their long-term moving average historical norms. Using a panel data set of 174 countries over the years 1960 to 2014, we find that per-capita real output growth is adversely affected by persistent changes in the temperature above or below its historical norm, but we do not obtain any statistically significant effects for changes in precipitation. We also show that the marginal effects of temperature shocks vary across climates and income groups. Our counterfactual analysis suggests that a persistent increase in average global temperature by 0.04oC per year, in the absence of mitigation policies, reduces world real GDP per capita by more than 7 percent by 2100. On the other hand, abiding by the Paris Agreement goals, thereby limiting the temperature increase to 0.01oC per annum, reduces the loss substantially to about 1 percent. These effects vary significantly across countries depending on the pace of temperature increases and variability of climate conditions. The estimated losses would increase to 13 percent globally if country-specific variability of climate conditions were to rise commensurate with annual temperature increases of 0.04oC.
JEL Classifications: C33, O40, O44, O51, Q51, Q54
Key Words: Climate change, economic growth, adaptation, counterfactual analysis.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/Climate_Growth_210821.pdf
-
"Land Use Regulations, Migration and Rising House Price Dispersion in the U.S.", by Wukuang Cun and M. Hashem Pesaran. April 2018, revised October 2018
Abstract: This paper develops and solves a dynamic spatial equilibrium model of regional housing markets in which house prices are jointly determined with location-to-location migration flows. Agents optimize period-by-period and decide whether to remain where they are or migrate to a new location at the start of each period. The agent's optimal location choice and the resultant migration process is shown to be Markovian with the transition probabilities across all location pairs given as non-linear functions of wage and housing cost differentials, which are time varying and endogenously determined. On the supply side, in each location the construction firms build new houses by combining land and residential structures; with housing supplies endogenously responding to migration flows. The model can be viewed as an example of a dynamic network where regional housing markets interact with each other via migration flows that function as a source of spatial spill-overs. It is shown that the deterministic version of the model has a unique equilibrium and a unique balanced growth path. We estimate the state-level supplies of new residential land from the model using housing market and urban land acreage data. These estimates are shown to be significantly negatively correlated with the Wharton Residential Land Use Regulatory Index. The model can simultaneously account for the rise in house price dispersion and the interstate migration in the U.S.. Counterfactual simulations suggest that reducing either land supply differentials or migration costs could significantly lower house price dispersion.
JEL Classifications: E0, R23, R31
Key Words: House price dispersion, endogenous location choice, interstate migration, land-use restriction, spatial equilibrium.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/PC_Housing_Paper_2018_10_09.pdf
SSRN Working Paper Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3162399
-
"Matching Theory and Evidence on Covid-19 using a Stochastic Network SIR Model", by M. Hashem Pesaran and Cynthia Fan Yang, November 2020.
Abstract: This paper develops an individual-based stochastic network SIR model for the empirical analysis of the Covid-19 pandemic. It derives moment conditions for the number of infected and active cases for single as well as multigroup epidemic models. These moment conditions are used to investigate identification and estimation of recovery and transmission rates. The paper then proposes simple moment-based rolling estimates and shows them to be fairly robust to the well-known under-reporting of infected cases. Empirical evidence on six European countries match the simulated outcomes, once the under-reporting of infected cases is addressed. It is estimated that the number of reported cases could be between 3 to 9 times lower than the actual numbers. Counterfactual analysis using calibrated models for Germany and UK show that early intervention in managing the infection is critical in bringing down the reproduction numbers below unity in a timely manner.
JEL Classifications: C13, C15, C31, D85, I18, J18
Key Words: Covid-19, multigroup SIR model, basic and effective reproduction numbers, rolling window estimates of the transmission rate, method of moments, calibration and counterfactual analysis.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp20/PY_epidemic_network_Nov_10_2020.pdf
-
"Long-Term Macroeconomic Effects of Climate Change: A Cross-Country Analysis", by Matthew E. Kahn, Kamiar Mohaddes, Ryan N. C. Ng, M. Hashem Pesaran, Mehdi Raissi and Jui-Chung Yang, CESifo Working Paper No. 7738, July 2019.
Abstract: We study the long-term impact of climate change on economic activity across countries, using a stochastic growth model where labour productivity is affected by country-specific climate variables-defined as deviations of temperature and precipitation from their historical norms. Using a panel data set of 174 countries over the years 1960 to 2014, we find that per-capita real output growth is adversely affected by persistent changes in the temperature above or below its historical norm, but we do not obtain any statistically significant effects for changes in precipitation. Our counterfactual analysis suggests that a persistent increase in average global temperature by 0.04℃ per year, in the absence of mitigation policies, reduces world real GDP per capita by 7.22 percent by 2100. On the other hand, abiding by the Paris Agreement, thereby limiting the temperature increase to 0.01℃ per annum, reduces the loss substantially to 1.07 percent. These effects vary significantly across countries. We also provide supplementary evidence using data on a sample of 48 U.S. states between 1963 and 2016, and show that climate change has a long-lasting adverse impact on real output in various states and economic sectors, and on labour productivity and employment.
JEL Classifications: C33, O40, O44, O51, Q51, Q54
Key Words: Climate change, economic growth, adaptation, counterfactual analysis.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp19/Climate Growth_190701.pdf
-
"Measurement of Factor Strength: Theory and Practice", by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, forthcoming in Journal of Applied Econometrics, CESifo Working Paper No. tbc, May 2021
Abstract: This paper proposes an estimator of factor strength and establishes its consistency and asymptotic distribution. The estimator is based on the number of statistically significant factor loadings, taking multiple testing into account. Both cases of observed, and unobserved factors are considered. The small sample properties of the proposed estimator are investigated using Monte Carlo experiments. It is shown that the proposed estimation and inference procedures perform well, and have excellent power properties, especially when the factor strength is sufficiently high. Empirical applications to factor models for asset returns show that out of 146 factors recently considered in the literature, only the market factor is truly strong, while all other factors are at best semi-strong, with their strength varying considerably over time. Similarly, we only find evidence of semi-strong factors using a large number of U.S. macroeconomic indicators.
JEL Classifications: C38, E20, G20
Key Words: Factor models, factor strength, measures of pervasiveness, cross-sectional dependence, market factor, macroeconomic shocks
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp21/Factor_strength_7_May_2021.pdf
Codes and Data: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp21/BKP_JAE_May2021_Simulations-Empirics.zip
-
"A Counterfactual Economic Analysis of Covid-19 Using a Threshold Augmented Multi-Country Model", by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, Mehdi Raissi, and Alessandro Rebucci, September 2020, revised May 2021.
Abstract: This paper develops a threshold-augmented dynamic multi-country model (TG-VAR) to quantify the macroeconomic effects of the Covid-19 pandemic. We show that there exist threshold effects in the relationship between output growth and excess global volatility at individual country levels in a significant majority of advanced economies and several emerging markets. We then estimate a more general multi-country model augmented with these threshold effects as well as long term interest rates, oil prices, exchange rates and equity returns to perform counterfactual analyses. We distinguish common global factors from trade-related spillovers, and identify the Covid-19 shock using GDP growth projection revisions of the IMF in 2020Q1. We account for sample uncertainty by bootstrapping the multi-country model estimated over four decades of quarterly observations. Our results show that, without policy support, the Covid-19 pandemic would cause a significant and long-lasting fall in world output, with outcomes that are quite heterogenous across countries and regions. While the impact on China and other emerging Asian economies are estimated to be less severe, the United Kingdom, and several other advanced economies may experience deeper and longer-lasting effects. Non-Asian emerging markets stand out for their vulnerability. We show that no country is immune to the economic fallout of the pandemic because of global inter-connections as evidenced by the case of Sweden. We also find that long-term interest rates could temporarily fall below their pre-Covid-19 lows in core advanced economies, but this does not seem to be the case in emerging markets.
JEL Classifications: C32, E44, F44
Key Words: Threshold-augmented Global VAR (TGVAR), international business cycle, Covid-19, global volatility, threshold effects
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/TGVAR_COVID-19_210528.pdf
VOXeu Article: https://voxeu.org/article/economic-consequences-covid-19-multi-country-analysis
-
"An Augmented Anderson-Hsiao Estimator for Dynamic Short-T Panels", by Alexander Chudik and M. Hashem Pesaran, CESifo WP no. 6688. October 2017, revised March 2021
Abstract: This paper introduces the idea of self-instrumenting endogenous regressors in settings when the correlation between these regressors and the errors can be derived and used to bias-correct the moment conditions. The resulting bias-corrected moment conditions are less likely to be subject to the weak instrument problem and can be used on their own or in conjunction with other available moment conditions to obtain more efficient estimators. This approach can be applied to estimation of a variety of models such as spatial and dynamic panel data models. This paper focuses on the latter, and proposes a new estimator for short T dynamic panels by augmenting Anderson and Hsiao (AAH) estimator with bias-corrected quadratic moment conditions in first differences which substantially improve the small sample performance of the AH estimator without sacrificing on the generality of its underlying assumptions regarding the fixed effects, initial values, and heteroskedasticity of error terms. Using Monte Carlo experiments it is shown that AAH estimator represents a substantial improvement over the AH estimator and more importantly it performs well even when compared to Arellano and Bond and Blundell and Bond (BB) estimators that are based on more restrictive assumptions, and continues to have satisfactory performance in cases where the standard GMM estimators are inconsistent. Finally, to decide between AAH and BB estimators we also propose a Hausman type test which is shown to work well when T is small and n sufficiently large.
JEL Classifications: C12, C13, C23.
Key Words: Short-T Dynamic Panels, GMM, Bias-Corrected Moment Conditions, BMM, Self-Instrumenting, Nonlinear Moment Conditions, Panel VARs, Hausman Test, Monte Carlo Evidence.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp21/CP_BMM_2021_Mar_23.pdf
Code and Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp21/codes_and_data.zip
-
"Short T Dynamic Panel Data Models with Individual, Time and Interactive Effects", by Kazuhiko Hayakawa, M. Hashem Pesaran and L. Vanessa Smith, September 2018, revised February 2020
Abstract: This paper proposes a quasi maximum likelihood (QML) estimator for short T dynamic fixed effects panel data models allowing for interactive effects through a multi-factor error structure. The proposed estimator is robust to the heterogeneity of the initial values and common unobserved effects, whilst at the same time allowing for standard fixed and time effects. It is applicable to both stationary and unit root cases. Order conditions for identification of the number of interactive effects are established, and conditions are derived under which the parameters are almost surely locally identified. It is shown that global identification is possible only when the model does not contain lagged dependent variables. The QML estimator is proven to be consistent and asymptotically normally distributed. A sequential multiple testing likelihood ratio procedure is also proposed for estimation of the number of factors which is shown to be consistent. Finite sample results obtained from Monte Carlo simulations show that the proposed procedure for determining the number of factors performs very well and the QML estimator has small bias and RMSE, and correct empirical size in most settings. The practical use of the QML approach is illustrated by means of two empirical applications from the literature on cross county crime rates and cross country growth regressions.
JEL Classifications: C12, C13, C23.
Key Words: short T dynamic panels, unobserved common factors, quasi maximum likelihood, interactive effects, multiple testing, sequential likelihood ratio tests, crime rate, growth regressions.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp20/HPS_11Feb20.pdf
SSRN Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3268434
-
"Regional Heterogeneity and U.S. Presidential Elections: Real-Time 2020 Forecasts and Evaluation", by Rashad Ahmed and M. Hashem Pesaran, October 2020, revised April 2021.
Abstract: This paper exploits cross-sectional variation at the level of U.S. counties to generate real-time forecasts for the 2020 U.S. presidential election. The forecasting models are trained on data covering the period 2000-2016, using high-dimensional variable selection techniques. Our county-based approach contrasts the literature that focuses on national and state level data but uses longer time periods to train their models. The paper reports forecasts of popular and electoral college vote outcomes and provides a detailed ex post evaluation of the forecasts released in real time prior to the election. It is shown that all of these forecasts outperform autoregressive benchmarks, with a pooled national model using One-Covariate-at-a-time-Multiple-Testing (OCMT) variable selection significantly outperforming all models in forecasting both the U.S. mainland national vote share and electoral college outcomes (forecasting 236 electoral votes for the Republican party compared to 232 realized). This paper also shows that key determinants of voting outcomes at the county level include incumbency effects, unemployment, poverty, educational attainment, house price changes, and international competitiveness. The results are also supportive of myopic voting: economic uctuations realized a few months before the election tend to be more powerful predictors of voting outcomes than their long-horizon analogues.
JEL Classifications: C53, C55, D72
Key Words: Real-time Forecasts, Popular and Electoral College Votes, Simultaneity, High Dimensional Forecasting Models, Lasso, One Covariate at a time Multiple Testing, OCMT.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp21/AhmedPesaran_Elections-Apr-28-2021.pdf
Reference: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp20/AhmedPesaran_Elections-Oct-18-2020.pdf
-
"A Counterfactual Economic Analysis of Covid-19 Using a Threshold Augmented Multi-Country Model", by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, Mehdi Raissi, and Alessandro Rebucci, September 2020.
Abstract: This paper develops a threshold-augmented dynamic multi-country model (TG-VAR) to quantify the macroeconomic effects of Covid-19. We show that there exist threshold effects in the relationship between output growth and excess global volatility at individual country levels in a significant majority of advanced economies and in the case of several emerging markets. We then estimate a more general multi-country model augmented with these threshold effects as well as long term interest rates, oil prices, exchange rates and equity returns to perform counterfactual analyses. We distinguish common global factors from trade-related spillovers, and identify the Covid-19 shock using GDP growth forecast revisions of the IMF in 2020Q1. We account for sample uncertainty by bootstrapping the multi-country model estimated over four decades of quarterly observations. Our results show that the Covid-19 pandemic will lead to a significant fall in world output that is most likely long-lasting, with outcomes that are quite heterogenous across countries and regions. While the impact on China and other emerging Asian economies are estimated to be less severe, the United States, the United Kingdom, and several other advanced economies may experience deeper and longer-lasting effects. Non-Asian emerging markets stand out for their vulnerability. We show that no country is immune to the economic fallout of the pandemic because of global interconnections as evidenced by the case of Sweden. We also find that long-term interest rates could fall significantly below their recent lows in core advanced economies, but this does not seem to be the case in emerging markets.
JEL Classifications: C32, E44, F44
Key Words: Threshold-augmented Global VAR (TGVAR), international business cycle, Covid-19, global volatility, threshold effects
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp20/TGVAR_COVID-19_200917_WP.pdf
VOXeu Article: https:/voxeu.org/article/economic-consequences-covid-19-multi-country-analysis
-
"Variable Selection and Forecasting in High Dimensional Linear Regressions with Structural Breaks", by Alexander Chudik, M. Hashem Pesaran and Mahrad Sharifvaghe, July 2020.
Abstract: This paper is concerned with problem of variable selection and forecasting in the presence of parameter instability. There are a number of approaches proposed for forecasting in the presence of breaks, including the use of rolling windows or exponential down-weighting. However, these studies start with a given model specification and do not consider the problem of variable selection. It is clear that, in the absence of breaks, researchers should weigh the observations equally at both variable selection and forecasting stages. In this study, we investigate whether or not we should use weighted observations at the variable selection stage in the presence of structural breaks, particularly when the number of potential covariates is large. Amongst the extant variable selection approaches we focus on the recently developed One Covariate at a time Multiple Testing (OCMT) method that allows a natural distinction between the selection and forecasting stages, and provide theoretical justification for using the full (not down-weighted) sample in the selection stage of OCMT and down-weighting of observations only at the forecasting stage (if needed). The benefits of the proposed method are illustrated by empirical applications to forecasting output growths and stock market returns.
JEL Classifications: C22, C52, C53, C55
Key Words: Time-varying parameters, structural breaks, high-dimensionality, multiple testing, variable selection, one covariate at a time multiple testing (OCMT), forecasting
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp20/CPS_OCMT_Break_Forecatsing_07_23_2020.pdf
-
"A Bias-Corrected Method of Moments Approach to Estimation of Dynamic Short-T Panels", by Alexander Chudik and M. Hashem Pesaran, CESifo WP no. 6688. October 2017
Abstract: This paper contributes to the GMM literature by introducing the idea of self-instrumenting target variables instead of searching for instruments that are uncorrelated with the errors, in cases where the correlation between the target variables and the errors can be derived. The advantage of the proposed approach lies in the fact that, by construction, the instruments have maximum correlation with the target variables and the problem of weak instrument is thus avoided. The proposed approach can be applied to estimation of a variety of models such as spatial and dynamic panel data models. In this paper we focus on the latter and consider both univariate and multivariate panel data models with short time dimension. Simple Bias-corrected Methods of Moments (BMM) estimators are proposed and shown to be consistent and asymptotically normal, under very general conditions on the initialization of the processes, individual-specific effects, and error variances allowing for heteroscedasticity over time as well as cross-sectionally. Monte Carlo evidence document BMM's good small sample performance across different experimental designs and sample sizes, including in the case of experiments where the system GMM estimators are inconsistent. We also find that the proposed estimator does not suffer size distortions and has satisfactory power performance as compared to other estimators.
JEL Classifications: C12, C13, C23.
Key Words: Short-T Dynamic Panels, GMM, Weak Instrument Problem, Quadratic Moment Conditions, Panel VARs, Monte Carlo Evidence.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/CP_BMM_2017_Sept20wp.pdf
-
"General Diagnostic Tests for Cross-sectional Dependence in Panels", by M. Hashem Pesaran, forthcoming in Empirical Economics, May 2020, Volume 35, Issue 3, pp. 294-314.
Abstract: This paper proposes simple tests of error cross-sectional dependence which are applicable to a variety of panel data models, including stationary and unit root dynamic heterogeneous panels with short T and large N. The proposed tests are based on the average of pair-wise correlation coefficients of the OLS residuals from the individual regressions in the panel and can be used to test for cross-sectional dependence of any fixed order p, as well as the case where no a priori ordering of the cross-sectional units is assumed, referred to as CD(p) and CD tests, respectively. Asymptotic distribution of these tests is derived and their power function analyzed under different alternatives. It is shown that these tests are correctly centred for fixed N and T and are robust to single or multiple breaks in the slope coefficients and/or error variances. The small sample properties of the tests are investigated and compared to the Lagrange multiplier test of Breusch and Pagan using Monte Carlo experiments. It is shown that the tests have the correct size in very small samples and satisfactory power, and, as predicted by the theory, they are quite robust to the presence of unit roots and structural breaks. The use of the CD test is illustrated by applying it to study the degree of dependence in per capita output innovations across countries within a given region and across countries in different regions. The results show significant evidence of cross-dependence in output innovations across many countries and regions in the World.
JEL Classifications: C12, C13, C33
Key Words: Cross-sectional dependence; Spatial dependence; Diagnostic tests; Dynamic heterogenous panels; Empirical growth.
Full Text: https://doi.org/10.1007/s00181-020-01875-7
-
"Estimation and Inference in Spatial Models with Dominant Units", by M. Hashem Pesaran and Cynthia Fan Yang, forthcoming in Journal of Econometrics, April 2020
Abstract: In spatial econometrics literature estimation and inference are carried out assuming that the matrix of spatial or network connections has uniformly bounded absolute column sums in the number of units, n, in the network. This paper relaxes this restriction and allows for one or more units to have pervasive effects in the network. The linear-quadratic central limit theorem of Kelejian and Prucha (2001) is generalized to allow for such dominant units, and the asymptotic properties of the GMM estimators are established in this more general setting. A new bias-corrected method of moments (BMM) estimator is also proposed that avoids the problem of weak instruments by self-instrumenting the spatially lagged dependent variable. Both cases of homoskedastic and heteroskedastic errors are considered and the associated estimators are shown to be consistent and asymptotically normal, depending on the rate at which the maximum column sum of the weights matrix rises with n. The small sample properties of GMM and BMM estimators are investigated by Monte Carlo experiments and shown to be satisfactory. An empirical application to sectoral price changes in the US over the pre-and post-2008 financial crisis is also provided. It is shown that the share of capital can be estimated reasonably well from the degree of sectoral interdependence using the input-output tables, despite the evidence of dominant sectors being present in the US economy.
JEL Classifications: C13, C21, C23, R15.
Key Words: SAR models, central limit theorems for linear-quadratic forms, dominant units, heteroskedastic errors, bias-corrected method of moments, US input-output tables, capital share
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp20/Final_JoE_PY_Spatial_model_with_dominant_units_April_2020.pdf
Replication Files: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp20/PY_SAR_BMM_replication_files_June_2020.zip
Readme: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp20/Readme.docx
-
"Detection of Units with Pervasive Effects in Large Panel Data Models", by George Kapetanios, M. Hashem Pesaran and Simon Reese, forthcoming in Journal of Econometrics, March 2020, CESifo Working Papers No. 7401.
Abstract: The importance of units that influence a large number of other units in a network has become increasingly recognized in the literature. In this paper we propose a new method to detect such pervasive units by basing our analysis on unit-specific residual error variances subject to suitable adjustments due to the multiple testing issues involved. Accordingly, a sequential multiple testing (SMT) procedure is proposed, which allows identification of pervasive units (if any) without a priori knowledge of the interconnections amongst cross-section units or availability of a short list of candidate units to search over. The proposed method is applicable even if the cross section dimension exceeds the time series dimension, and most importantly it could end up with none of the units selected as pervasive when this is in fact the case. The SMT procedure exhibits satisfactory small-sample performance in Monte Carlo simulations and compares well relative to existing approaches. We apply the SMT detection method to sectoral indices of U.S. industrial production, U.S. house price changes by states, and the rates of change of real GDP and real equity prices across the world's largest economies.
JEL Classifications: C18, C23, C55.
Key Words: Pervasive units, factor models, systemic risk, multiple testing, sequential procedure, cross-sectional dependence.
Full Text: https://doi.org/10.1016/j.jeconom.2020.05.001
-
"Estimation and Inference for Spatial Models with Heterogeneous Coefficients: An Application to U.S. House Prices", by Michele Aquaro, Natalia Bailey and M. Hashem Pesaran, forthcoming in Journal of Applied Econometrics, CESifo WP Series No. 7542. This paper was previously titled “Quasi-maximum likelihood estimation of spatial models with heterogeneous coefficient” (CESifo WP Series No. 5428)
Abstract: This paper considers the estimation and inference of spatial panel data models with heterogeneous spatial lag coefficients, with and without weakly exogenous regressors, and subject to heteroskedastic errors. A quasi maximum likelihood (QML) estimation procedure is developed and the conditions for identification of the spatial coefficients are derived. The QML estimators of individual spatial coefficients, as well as their mean group estimators, are shown to be consistent and asymptotically normal. Small sample properties of the proposed estimators are investigated by Monte Carlo simulations and results are in line with the paper's key theoretical findings even for panels with moderate time dimensions and irrespective of the number of cross section units. A detailed empirical application to U.S. house price changes during the 1975-2014 period shows a significant degree of heterogeneity in spatio-temporal dynamics over the 338 Metropolitan Statistical Areas considered.
JEL Classifications: C21, C23
Key Words: Spatial panel data models, heterogeneous spatial lag coefficients, identification, quasi maximum likelihood (QML) estimators, house price changes, Metropolitan Statistical Areas.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp20/ABP_June_2020-HSAR-paper-JAE.pdf
Data and Codes: http://qed.econ.queensu.ca/jae/datasets/aquaro001/
-
"Econometric Analysis of Production Networks with Dominant Units", by M. Hashem Pesarann and Cynthia Fan Yang, forthcoming in Journal of Econometrics, March 2019
Abstract: This paper introduces the notions of strongly and weakly dominant units for networks, and shows that pervasiveness of shocks to a network is measured by the degree of dominance of its most pervasive unit; shown to be equivalent to the inverse of the shape parameter of the power law fitted to the network outdegrees. New cross- section and panel extremum estimators of the degree of dominance in networks are proposed, and their asymptotic properties investigated. The small sample properties of the proposed estimators are examined by Monte Carlo experiments, and their use is illustrated by an empirical application to US input-output tables.
JEL Classifications: C12, C13, C23, C67, E32
Key Words: Aggregate fluctuations, strongly and weakly dominant units, spatial models, outdegrees, degree of pervasiveness, power law, input-output tables, US economy.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp19/PY_Production_network_March_10_2019.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/Online-supplement-PY-Production-network-4-August-2017.pdf
Readme: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/Readme-PY-Production-network-4-August-2017.pdf
Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/Data-PY-Production-network-4-August-2017.zip
Codes: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/Codes-PY-Production-network-4-August-2017.zip
-
"Measurement of Factor Strength: Theory and Practice", by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, CESifo Working Paper No. tbc, February 2020.
Abstract: This paper proposes an estimator of factor strength and establishes its consistency and asymptotic distribution. The proposed estimator is based on the number of statistically significant factor loadings, taking account of the multiple testing problem. We focus on the case where the factors are observed which is of primary interest in many applications in macroeconomics and finance. We also consider using cross section averages as a proxy in the case of unobserved common factors. We face a fundamental factor identification issue when there are more than one unobserved common factors. We investigate the small sample properties of the proposed estimator by means of Monte Carlo experiments under a variety of scenarios. In general, we find that the estimator, and the associated inference, perform well. The test is conservative under the null hypothesis, but, nevertheless, has excellent power properties, especially when the factor strength is sufficiently high. Application of the proposed estimation strategy to factor models of asset returns shows that out of 146 factors recently considered in the finance literature, only the market factor is truly strong, while all other factors are at best semi-strong, with their strength varying considerably over time. Similarly, we only find evidence of semi-strong factors in an updated version of the Stock and Watson (2012) macroeconomic dataset.
JEL Classifications: C38, E20, G20
Key Words: Factor models, factor strength, measures of pervasiveness, cross-sectional dependence, market factor.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp20/Factor_strength_25_Feb_2020.pdf
-
"Identifying Global and National Output and Fiscal Policy Shocks Using a GVAR", by Alexander Chudik, M. Hashem Pesaran and Kamiar Mohaddes, December 2018
Abstract: The paper contributes to the growing global VAR (GVAR) literature by showing how global and national shocks can be identified within a GVAR framework. The usefulness of the proposed approach is illustrated in an application to the analysis of the interactions between public debt and real output growth in a multicountry setting, and the results are compared to those obtained from standard single country VAR analysis. We find that on average (across countries) global shocks explain about one third of the long-horizon forecast error variance of output growth, and about one fifth of the long run variance of the rate of change of debt-to-GDP. Evidence on the degree of cross-sectional dependence in these variables and their innovations are exploited to identify the global shocks, and priors are used to identify the national shocks within a Bayesian framework. It is found that posterior median debt elasticity with respect to output is much larger when the rise in output is due to a fiscal policy shock, as compared to when the rise in output is due to a positive technology shock. The cross country average of the median debt elasticity is 1.58 when the rise in output is due to a fiscal expansion as compared to 0.75 when the rise in output follows from a favorable output shock.
JEL Classifications: C30, E62, H6.
Key Words: Factor-augmented VARs, Global VARs, identification of global and country-specific shocks, Bayesian analysis, public debt and output growth, debt elasticity.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/CMP_GVAR_debt_2018_12_26_rs.pdf
-
"Uncertainty and Economic Activity: A Multi-Country Perspective", by Ambrogio Cesa-Bianchi, M. Hashem Pesaran and Alessandro Rebucci, forthcoming in The Review of Financial Studies, June 2019
Abstract: This paper develops an asset pricing model with heterogeneous exposure to a persistent world growth factor to identify global growth and financial shocks in a multi-country panel VAR model for the analysis of the relationship between volatility and the business cycle. The econometric estimates yield three sets of empirical results regarding (i) the importance of global growth for the interpretation of the correlation between volatility and growth over the business cycle and the possible presence of omitted variable bias in single-country VARs studies, (ii) the extent to which output shocks drive volatility, and (iii) the transmission of volatility shocks to output growth.
JEL Classifications: E44, F44, G15
Key Words: Uncertainty, Business Cycle, Global Shocks, Multi-Country Asset Pricing Model, Panel VAR, Identification, Realized Volatility, Impulse Responses.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp19/CPR_FinalManuscript.pdf
Supplement: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp19/CPR_Supplement.pdf
Data: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp19/REPLICATIONFILES-Submittedon19-08-2019.zip
-
"Estimation and Inference in Spatial Models with Dominant Units", by M. Hashem Pesaran and Cynthia Fan Yang, March 2019, revised January 2020
Abstract: In spatial econometrics literature estimation and inference are carried out assuming that the matrix of spatial or network connections has uniformly bounded absolute column sums in the number of units, n, in the network. This paper relaxes this restriction and allows for one or more units to have pervasive effects in the network. The linear-quadratic central limit theorem of Kelejian and Prucha (2001) is generalized to allow for such dominant units, and the asymptotic properties of the GMM estimators are established in this more general setting. A new bias-corrected method of moments (BMM) estimator is also proposed that avoids the problem of weak instruments by self-instrumenting the spatially lagged dependent variable. Both cases of homoskedastic and heteroskedastic errors are considered and the associated estimators are shown to be consistent and asymptotically normal, depending on the rate at which the maximum column sum of the weights matrix rises with n. The small sample properties of GMM and BMM estimators are investigated by Monte Carlo experiments and shown to be satisfactory. An empirical application to sectoral price changes in the US over the pre and post-2008 financial crisis is also provided. It is shown that the share of capital can be estimated reasonably well from the degree of sectoral interdependence using the input-output tables, despite the evidence of dominant sectors being present in the US economy.
JEL Classifications: C13, C21, C23, R15.
Key Words: spatial autoregressive models, central limit theorems for linear-quadratic forms, dominant units, heteroskedastic errors, GMM, bias-corrected method of moments (BMM), US input-output analysis, capital share.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp20/PY_SAR_BMM_Main_and_Supplement_15_Jan_2020.pdf
Replication Files: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp20/PY_SAR_BMM_replication_files_15_Jan_2020.zip
-
"Estimation and Inference for Spatial Models with Heterogeneous Coefficients: An Application to U.S. House Prices", by Michele Aquaro, Natalia Bailey and M. Hashem Pesaran, CESifo WP Series No. 7542, March 2019, revised May 2020. This paper was previously titled “Quasi-maximum likelihood estimation of spatial models with heterogeneous coefficient” (CESifo WP Series No. 5428)
Abstract: This paper considers the problem of identification, estimation and inference in the case of spatial panel data models with heterogeneous spatial lag coefficients, with and without (weakly) exogenous regressors, and subject to heteroskedastic errors. A quasi maximum likelihood (QML) estimation procedure is developed and the conditions for identification of spatial coefficients are derived. Regularity conditions are established for the QML estimators of individual spatial coefficients, as well as their means (the mean group estimators), to be consistent and asymptotically normal. Small sample properties of the proposed estimators are investigated by Monte Carlo simulations for Gaussian and non-Gaussian errors, and with spatial weight matrices of differing degrees of sparsity. The simulation results are in line with the paper's key theoretical findings even for panels with moderate time dimensions and irrespective of the number of cross section units. An empirical application to U.S. house price changes during the 1975-2014 period shows a significant degree of heterogeneity in spatio-temporal spill-over effects over the 338 Metropolitan Statistical Areas considered.
JEL Classifications: C21, C23
Key Words: Spatial panel data models, heterogeneous spatial lag coefficients, identification, quasimaximum likelihood (QML) estimators, non-Gaussian errors, house price changes, Metropolitan Statistical Areas.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp20/ABP_12_May_2020.pdf
-
"Detection of Units with Pervasive Effects in Large Panel Data Models", by George Kapetanios, M. Hashem Pesaran and Simon Reese, CESifo Working Papers No. 7401, November 2018, revised April 2019
Abstract: The importance of units with pervasive impacts on a large number of other units in a network has become increasingly recognized in the literature. In this paper we propose a new method to detect such pervasive units by basing our analysis on unit-specific residual error variances in the context of a standard factor model, subject to suitable adjustments due to multiple testing. Our proposed method allows us to estimate and identify pervasive units having neither a priori knowledge of the interconnections amongst cross-section units nor a short list of candidate units. It is applicable even if the cross section dimension exceeds the time dimension, and most importantly it could end up with none of the units selected as pervasive when this is in fact the case. The sequential multiple testing procedure proposed exhibits satisfactory small-sample performance in Monte Carlo simulations and compares well relative to existing approaches. We apply the proposed detection method to sectoral indices of US industrial production, US house price changes by states, and the rates of change of real GDP and real equity prices across the world's largest economies.
JEL Classifications: C18, C23, C55.
Key Words: Pervasive units, factor models, systemic risk, cross-sectional dependence.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp19/KPR_dominantunits_23_April_2019.pdf
-
"Estimation and inference for spatial models with heterogeneous coefficients: an application to U.S. house prices", by Michele Aquaro, Natalia Bailey and M. Hashem Pesaran, CESifo WP Series No. 7542, March 2019. This paper was previously titled “Quasi-maximum likelihood estimation of spatial models with heterogeneous coefficient” (CESifo WP Series No. 5428)
Abstract: This paper considers the problem of identification, estimation and inference in the case of spatial panel data models with heterogeneous spatial lag coefficients, with and without (weakly) exogenous regressors, and subject to heteroskedastic errors. A quasi maximum likelihood (QML) estimation procedure is developed and the conditions for identification of spatial coefficients are derived. Regularity conditions are established for the QML estimators of individual spatial coefficients, as well as their means (the mean group estimators), to be consistent and asymptotically normal. Small sample properties of the proposed estimators are investigated by Monte Carlo simulations for Gaussian and non-Gaussian errors, and with spatial weight matrices of differing degrees of sparsity. The simulation results are in line with the paper's key theoretical findings even for panels with moderate time dimensions, irrespective of the number of cross section units. An empirical application to U.S. house price changes during the 1975-2014 period shows a significant degree of heterogeneity in spill-over effects over the 338 Metropolitan Statistical Areas considered.
JEL Classifications: C210, C230
Key Words: spatial panel data models, heterogeneous spatial lag coefficients, identification, quasi maximum likelihood (QML) estimators, non-Gaussian errors, house price changes, Metropolitan Statistical Areas.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp19/Aquaro_Bailey_Pesaran_Estimation_and_inference_for_spatial_models_with_cesifo_wp7542.pdf
-
"Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Quantile Regression Models", by Matthew Harding, Carlos Lamarche and M. Hashem Pesaran, forthcoming in Journal of Applied Econometrics, December 2019
Abstract: This paper proposes a quantile regression estimator for a heterogeneous panel model with lagged dependent variables and interactive effects. The paper adopts the Common Correlated Effects (CCE) approach proposed by Pesaran (2006) and Chudik and Pesaran (2015) and demonstrates that the extension to the estimation of dynamic quantile regression models is feasible under similar conditions to the ones used in the literature. The new quantile regression estimator is shown to be consistent and its asymptotic distribution is derived. Monte Carlo studies are carried out to study the small sample behavior of the proposed approach. The evidence shows that the estimator can significantly improve on the performance of existing estimators as long as the time series dimension of the panel is large. We present an application to the evaluation of Time-of-Use pricing using a large randomized control trial.
JEL Classifications: C21, C31, C33, D12, L94
Key Words: Common Correlated Effects; Dynamic Panel; Quantile Regression; Smart Meter; Randomized Experiment.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp20/qmg40-rev21.pdf
Appendix: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp20/qmg40-rev21-online-appendix.pdf
-
"Short T Dynamic Panel Data Models with Individual and Interactive Time Effects", by Kazuhiko Hayakawa, M. Hashem Pesaran and L. Vanessa Smith, September 2018
Abstract: This paper proposes a quasi maximum likelihood estimator for short T dynamic fixed effects panel data models allowing for interactive time effects through a multifactor error structure. The proposed estimator is robust to the heterogeneity of the initial values and common unobserved effects, whilst at the same time allowing for standard fixed and time effects. It is applicable to both stationary and unit root cases. Order conditions for identification of the number of interactive effects are established, and conditions are derived under which the parameters are almost surely locally identified. It is shown that global identification is possible only when the model does not contain lagged dependent variables. The QML estimator is proven to be consistent and asymptotically normally distributed. A sequential multiple testing likelihood ratio procedure is also proposed for estimation of the number of factors which is shown to be consistent. Finite sample results obtained from Monte Carlo simulations show that the proposed procedure for determining the number of factors performs very well and the quasi ML estimator has small bias and RMSE, and correct empirical size even when the number of factors is estimated. An empirical application, revisiting the growth convergence literature is also provided.
JEL Classifications: C12, C13, C23.
Key Words: short T dynamic panels, unobserved common factors, quasi maximum likelihood, interactive time effects, multiple testing, sequential likelihood ratio tests, output and growth convergence.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/HPS_2_September_2018.pdf
-
"Estimation and Inference in Spatial Models with Dominant Units", by M. Hashem Pesaran and Cynthia Fan Yang, March 2019
Abstract: Estimation and inference in the spatial econometrics literature are carried out assuming that the matrix of spatial or network connections has uniformly bounded absolute column sums in the number of cross-section units, n. In this paper, we consider spatial models where this restriction is relaxed. The linear-quadratic central limit theorem of Kelejian and Prucha (2001) is generalized and then used to establish the asymptotic properties of the GMM estimator due to Lee (2007) in the presence of dominant units. A new Bias-Corrected Method of Moments estimator is also proposed that avoids the problem of weak instruments by self-instrumenting the spatially lagged dependent variable. Both estimators are shown to be consistent and asymptotically normal, depending on the rate at which the maximum column sum of the weights matrix rises with n. The small sample properties of the estimators are investigated by Monte Carlo experiments and shown to be satisfactory. An empirical application to sectoral price changes in the US over the pre- and post-2008 financial crisis is also provided. It is shown that the share of capital can be estimated reasonably well from the degree of sectoral interdependence using the input-output tables, despite the evidence of dominant sectors being present in the US economy.
JEL Classifications: C13, C21, C23, R15.
Key Words: spatial autoregressive models, central limit theorems for linear-quadratic forms, dominant units, GMM, bias-corrected method of moments (BMM), US input- output analysis, capital share.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp19/PY_SAR_BMM_Main_and_Appendix_March_10_2019.pdf
-
"Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Quantile Regression Models", by Matthew Harding, Carlos Lamarche and M. Hashem Pesaran. August 2018
Abstract: This paper proposes a quantile regression estimator for a heterogeneous panel model with lagged dependent variables and interactive effects. The paper adopts the Common Correlated Effects (CCE) approach proposed by Pesaran (2006) and Chudik and Pesaran (2015) and demonstrates that the extension to the estimation of dynamic quantile regression models is feasible under similar conditions to the ones used in the literature. We establish consistency and derive the asymptotic distribution of the new quantile regression estimator. Monte Carlo studies are carried out to study the small sample behavior of the proposed approach. The evidence shows that the estimator can significantly improve on the performance of existing estimators as long as the time series dimension of the panel is large. We present an application to the evaluation of Time-of-Use pricing using a large randomized control trial.
JEL Classifications: C21, C31, C33, D12, L94
Key Words: Common Correlated Effects; Dynamic Panel; Quantile Regression; Smart Meter; Randomized Experiment.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/LamarcheHardingPesaran_Dynamic_Panel_Quantile_Paper_and_Supplement_August_2018.pdf
-
"Exponent of Cross-sectional Dependence for Residuals", by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, forthcoming in Sankhya B. The Indian Journal of Statistics, April 2019
Abstract: In this paper we focus on estimating the degree of cross-sectional dependence in the error terms of a classical panel data regression model. For this purpose we propose an estimator of the exponent of cross-sectional dependence denoted by α, which is based on the number of non-zero pair-wise cross correlations of these errors. We prove that our estimator, ã, is consistent and derive the rate at which ã, approaches its true value. We evaluate the finite sample properties of the proposed estimator by use of a Monte Carlo simulation study. The numerical results are encouraging and supportive of the theoretical findings. Finally, we undertake an empirical investigation of α for the errors of the CAPM model and its Fama-French extensions using 10-year rolling samples from S&P 500 securities over the period Sept 1989 - May 2018.
JEL Classifications: C21, C32
Key Words: Pair-wise correlations, Cross-sectional dependence, Cross-sectional averages, Weak and strong factor models. CAPM and Fama-French Factors.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp19/BKP_res_paper_4_Apr_2019.pdf
-
"A Bayesian Analysis of Linear Regression Models with Highly Collinear Regressors", by M. Hashem Pesaran and Ron P. Smith, forthcoming in Econometrics and Statistics, October 2018
Abstract: Exact collinearity between regressors makes their individual coefficients not identified. But, given an informative prior, their Bayesian posterior means are well defined. Just as exact collinearity causes non-identification of the parameters, high collinearity can be viewed as weak identification of the parameters, which is represented, in line with the weak instrument literature, by the correlation matrix being of full rank for a finite sample size T, but converging to a rank deficient matrix as T goes to infinity. The asymptotic behaviour of the posterior mean and precision of the parameters of a linear regression model are examined in the cases of exactly and highly collinear regressors. In both cases the posterior mean remains sensitive to the choice of prior means even if the sample size is sufficiently large, and that the precision rises at a slower rate than the sample size. In the highly collinear case, the posterior means converge to normally distributed random variables whose mean and variance depend on the prior means and prior precisions. The distribution degenerates to fixed points for either exact collinearity or strong identification. The analysis also suggests a diagnostic statistic for the highly collinear case. Monte Carlo simulations and an empirical example are used to illustrate the main findings.
JEL Classifications: C11, C18
Key Words: Bayesian identification, multicollinear regressions, weakly identified regression coefficients, highly collinear regressors.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp18/PS_high_collinearity_6_October_2018.pdfNote: A previous version of the paper was distributed as CESifo Working Paper 6785 under the title of "Posterior Means and Precisions of the Coefficients in Linear Models with Highly Collinear Regressors"
-
"Uncertainty and Economic Activity: A Multi-Country Perspective", by Ambrogio Cesa-Bianchi, M. Hashem Pesaran and Alessandro Rebucci. February 2018
Abstract: Measures of economic uncertainty are countercyclical, but economic theory does not provide definite guidance on the direction of causation between uncertainty and the business cycle. This paper proposes a new multi-country approach to the analysis of the interaction between uncertainty and economic activity, without a priori restricting the direction of causality. We develop a multi-country version of the Lucas tree model with time-varying volatility and show that in addition to common technology shocks that affect output growth, higherorder moments of technology shocks are also required to explain the cross country variations of realized volatility. Using this theoretical insight, two common factors, a 'real' and a 'financial' one, are identified in the empirical analysis assuming different patterns of crosscountry correlations of country-specific innovations to real GDP growth and realized stock market volatility. We then quantify the absolute and the relative importance of the common factor shocks as well as country-specific volatility and GDP growth shocks. The paper highlights three main empirical findings. First, it is shown that most of the unconditional correlation between volatility and growth can be accounted for by the real common factor, which is proportional to world growth in our empirical model and linked to the risk-free rate. Second, the share of volatility forecast error variance explained by the real common factor and by country-specific growth shocks amounts to less than 5 percent. Third, shocks to the common financial factor explain about 10 percent of the growth forecast error variance, but when such shocks occur, their negative impact on growth is large and persistent. In contrast, country-specific volatility shocks account for less than 1-2 percent of the growth forecast error variance.
JEL Classifications: E44, F44, G15
Key Words: Uncertainty, Business Cycle, Common Factors, Real and Financial Global Shocks, Multi-Country, Identification, Realized Volatility.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/CPR_VOLATILITY_Feb7.pdf
-
"A Residual-based Threshold Method for Detection of Units that are Too Big to Fail in Large Factor Models", by George Kapetanios, M. Hashem Pesaran and Simon Reese, CESifo Working Papers No. 7401, November 2018
Abstract: The importance of units with pervasive impacts on a large number of other units in a network has become increasingly recognized in the literature. In this paper we propose a new method to detect such inuential or dominant units by basing our analysis on unit-speci c residual error variances in the context of a standard factor model, subject to suitable adjustments due to multiple testing. Our proposed method allows us to estimate and identify the dominant units without the a priori knowledge of the interconnections amongst the units, or using a short list of potential dominant units. It is applicable even if the cross section dimension exceeds the time dimension, and most importantly it could end up with none of the units selected as dominant when this is in fact the case. The sequential multiple testing procedure proposed exhibits satisfactory small-sample performance in Monte Carlo simulations and compares well relative to existing approaches. We apply the proposed detection method to sectoral indices of US industrial production, US house price changes by states, and the rates of change of real GDP and real equity prices across the worlds largest economies.
JEL Classifications: C18, C23, C55.
Key Words: Dominant units, factor models, systemic risk, cross-sectional dependence, networks.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/KPR_dominantunits_Nov_29_2018.pdf
-
"Mean Group Estimation in Presence of Weakly Cross-Correlated Estimators", by Alexander Chudik and M. Hashem Pesaran, forthcoming in Economics Letters, December 2018
Abstract: This paper extends the mean group (MG) estimator for random coefficient panel data models by allowing the underlying individual estimators to be weakly cross correlated. This can arise, for example, in panels with spatially correlated errors. We establish that the MG estimator is asymptotically correctly centered, and its asymptotic covariance matrix can be consistently estimated. In contrast with the homogeneous case, the random coefficient speci cation allows for correct inference even when nothing is known about the weak cross-sectional dependence of the errors.
JEL Classifications: C12, C13, C23.
Key Words: Mean Group Estimator, Cross Sectional Dependence, Spatial Models, Panel Data.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp18/ChudikPesaran_MG_2018Dec21.pdf
-
"Exponent of Cross-sectional Dependence for Residuals", by Natalia Bailey, George Kapetanios and M. Hashem Pesaran. August 2018
Abstract: In this paper we focus on estimating the degree of cross-sectional dependence in the error terms of a classical panel data regression model. For this purpose we propose an estimator of the exponent of cross-sectional dependence denoted by α, which is based on the number of non-zero pair-wise cross correlations of these errors. We prove that our estimator, ã, is consistent and derive the rate at which ã, approaches its true value. We evaluate the finite sample properties of the proposed estimator by use of a Monte Carlo simulation study. The numerical results are encouraging and supportive of the theoretical findings. Finally, we undertake an empirical investigation of α for the errors of the CAPM model and its Fama-French extensions using 10-year rolling samples from S&P 500 securities over the period Sept 1989 - May 2018.
JEL Classifications: C21, C32
Key Words: Pair-wise correlations, Cross-sectional dependence, Cross-sectional averages, Weak and strong factor models. CAPM and Fama-French Factors.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/BKP_res_paper_26_Aug_2018.pdf
-
"Quasi Maximum Likelihood Estimation of Spatial Models with Heterogeneous Coefficients", by Michele Aquaro, Natalia Bailey and M. Hashem Pesaran, CESifo WP Series No. 5428, June 2015
Abstract: This paper considers spatial autoregressive panel data models and extends their analysis to the case where the spatial coefficients differ across the spatial units. It derives conditions under which the spatial coefficients are identi ed and develops a quasi maximum likelihood (QML) estimation procedure. Under certain regularity conditions, it is shown that the QML estimators of individual spatial coefficients are consistent and asymptotically normally distributed when both the time and cross section dimensions of the panel are large. It derives the asymptotic covariance matrix of the QML estimators allowing for the possibility of non-Gaussian error processes. Small sample properties of the proposed estimators are investigated by Monte Carlo simulations for Gaussian and non-Gaussian errors, and with spatial weight matrices of differing degree of sparseness. The simulation results are in line with the paper's key theoretical findings and show that the QML estimators have satisfactory small sample properties for panels with moderate time dimensions and irrespective of the number of cross section units in the panel, under certain sparsity conditions on the spatial weight matrix.
JEL Classifications: C21, C23
Key Words: Spatial panel data models, heterogeneous spatial lag coefficients, identification, quasi maximum likelihood (QML) estimators, non-Gaussian errors.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/ABP_June_19_2015.pdf
-
"Econometric Analysis of Production Networks with Dominant Units", by M. Hashem Pesarann and Cynthia Fan Yang, October 2016, revised August 2017
Abstract: This paper considers production and price networks with unobserved common factors, and derives an exact expression for the rate at which aggregate fluctuations vary with the dimension of the network. It introduces the notions of strongly and weakly dominant and non-dominant units, and shows that at most a finite number of units in the network can be strongly dominant. The pervasiveness of a network is measured by the degree of dominance of the most pervasive unit in the network, and is shown to be equivalent to the inverse of the shape parameter of the power law fitted to the network outdegrees. New cross-section and panel extremum estimators for the degree of dominance of individual units in the network are proposed and their asymptotic properties investigated. Using Monte Carlo techniques, the proposed estimator is shown to have satisfactory small sample properties. An empirical application to US input-output tables spanning the period 1972 to 2007 is provided which suggests that no sector in the US economy is strongly dominant. The most dominant sector turns out to be the wholesale trade with an estimated degree of dominance ranging from 0.72 to 0.82 over the years 1972-2007.
JEL Classifications: C12, C13, C23, C67, E32
Key Words: Aggregate fluctuations, strongly and weakly dominant units, spatial models, outdegrees, degree of pervasiveness, power law, input-output tables, US economy.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/Main-paper-PY-Production-network-4-August-2017.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/Online-supplement-PY-Production-network-4-August-2017.pdf
Readme: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/Readme-PY-Production-network-4-August-2017.pdf
Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/Data-PY-Production-network-4-August-2017.zip
Codes: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/Codes-PY-Production-network-4-August-2017.zip
-
"Mean Group Estimation in Presence of Weakly Cross-Correlated Estimators", by Alexander Chudik and M. Hashem Pesaran, November 2018
Abstract: This paper extends the mean group (MG) estimator for random coefficient panel data models by allowing the underlying individual estimators to be weakly cross correlated. Weak cross-sectional dependence of the individual estimators can arise, for example, in panels with spatially correlated errors. We establish that the MG estimator is asymptotically correctly centered, and its asymptotic covariance matrix can be consistently estimated. The random coefficient specification allows for correct inference even when nothing is known about the weak cross-sectional dependence of the errors. This is in contrast to the well known homogenous case, where cross-sectional dependence of errors results in incorrect inference unless the nature of the cross-sectional error dependence is known and can be taken into account. Evidence on small sample performance of the MG estimators are provided using Monte Carlo experiments with both strictly and weakly exogenous regressors and cross-sectionally correlated innovations.
JEL Classifications: C12, C13, C23.
Key Words: Mean Group Estimator, Cross Sectional Dependence, Spatial Models, Panel Data.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/ChudikPesaran_MG_2018Nov14.pdf
-
"Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes", by M. Hashem Pesarann and Ida Johnsson, forthcoming in Journal of Business and Economic Statistics, August 2018
Abstract: This paper proposes a new double-question survey whereby an individual is presented with two sets of questions; one on beliefs about current asset values and another on price expectations. A theoretical asset pricing model with heterogeneous agents is advanced and the existence of a negative relationship between price expectations and asset valuations is established, and is then tested using survey results on equity, gold and house prices. Leading indicators of bubbles and crashes are proposed and their potential value is illustrated in the context of a dynamic panel regression of realized house price changes across key Metropolitan Statistical Areas (MSAs) in the US. In an out-of-sample forecasting exercise it is also shown that forecasts of house price changes (pooled across MSAs) that make use of bubble and crash indicators perform signi ficantly better than a benchmark model that only uses lagged and expected house price changes.
JEL Classifications: C83, D84, G12, G14.
Key Words: Price expectations, bubbles and crashes, house prices, belief valuations.
Full Text: https://doi.org/10.1080/07350015.2018.1513845
Supplementary Materials: https://www.dropbox.com/s/qe2efuf4tge89gk/Supplementary%20Materials%20for%20Review.zip?dl=0
Data: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp18/DQ-survey-data-Aug-2012-Jan-2013.zip
Read Me: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp18/readme.txt
-
"Half-Panel Jackknife Fixed Effects Estimation of Linear Panels with Weakly Exogenous Regressors", by Alexander Chudik, M. Hashem Pesarann and Jui-Chung Yang, SSRN Working Paper No. 281, forthcoming in Journal of Applied Econometrics, January 2018
Abstract: This paper considers estimation and inference in fixed effects (FE) linear panel regression models with lagged dependent variables and/or other weakly exogenous (or predetermined) regressors when N (the cross section dimension) is large relative to T (the time series dimension). The paper first derives a general formula for the bias of the FE estimator which is a generalization of the Nickell type bias derived in the literature for the pure dynamic panel data models. It shows that in the presence of weakly exogenous regressors, inference based on the FE estimator will result in size distortions unless N/T is suffciently small. To deal with the bias and size distortion of FE estimator when N is large relative to T, the use of half-panel Jackknife FE estimator is proposed and its asymptotic distribution is derived. It is shown that the bias of the proposed estimator is of order [code], and for valid inference it is only required that N/T[code], as N, T [code] jointly. Extensions to panel data models with time effects (TE), for balanced as well as unbalanced panels, are also provided. The theoretical results are illustrated with Monte Carlo evidence. It is shown that the FE estimator can suffer from large size distortions when N > T, with the proposed estimator showing little size distortions. The use of half-panel jackknife FE-TE estimator is illustrated with two empirical applications from the literature.
JEL Classifications: C32, E17, E32, F44, F47, O51, Q43.
Key Words: Panel Data Models, Weakly Exogenous Regressors, Lagged Dependent Variable, Fixed Effects, Time Effects, Unbalanced Panels, Half-Panel Jackknife, Bias Correction
Full Text: https://doi.org/10.1002/jae.2623
Readme file: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp18/readme_file_for_data_and_codes.txt
Data for the Empirical Section: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp18/cpy-data.zip
Computer codes: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp18/cpy-progs.zip
-
"Tests of Policy Interventions in DSGE Models", by M. Hashem Pesaran and Ron P. Smith, forthcoming in Oxford Bulletin of Economics and Statistics, October 2017.
Abstract: This paper considers tests of the effectiveness of a policy intervention, de ned as a change in the parameters of a policy rule, in the context of a macroeconometric dynamic stochastic general equilibrium (DSGE) model. We consider two types of intervention, fi rst the standard case of a parameter change that does not alter the steady state, and second one that does alter the steady state, e.g. the target rate of inflation. We consider two types of test, one a multi-horizon test, where the post-intervention policy horizon, H, is small and fi xed, and a mean policy effect test where H is allowed to increase without bounds. The multi-horizon test requires Gaussian errors, but the mean policy effect test does not. It is shown that neither of these two tests are consistent, in the sense that the the power of the tests does not tend to unity as H → ∞, unless the intervention alters the steady state. This follows directly from the fact that DSGE variables are measured as deviations from the steady state, and the effects of policy change on target variables decay exponentially fast. We investigate the size and power of the proposed mean effect test by simulating a standard three equation New Keynesian DSGE model. The simulation results are in line with our theoretical fi ndings and show that in all applications the tests have the correct size; but unless the intervention alters the steady state, their power does not go to unity with H.
JEL Classifications: C18, C54, E65.
Key Words: Counterfactuals, policy analysis, policy ineffectiveness test, macroeconomics.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp17/PS_on_PI_12_October_2017_main_paper.pdf
Supplement: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp17/PS_on_PI_12_October_2017_online_supplement.pdf
-
"A Multiple Testing Approach to the Regularisation of Large Sample Correlation Matrices", by Natalia Bailey, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.05, May 2014, revised September 2016
Abstract: This paper proposes a regularisation method for the estimation of large covariance matrices that uses insights from the multiple testing (MT) literature. The approach tests the statistical signi?cance of individual pair-wise correlations and sets to zero those elements that are not statistically significant, taking account of the multiple testing nature of the problem. The effective p-values of the tests are set as a decreasing function of N (the cross section dimension), the rate of which is governed by the maximum degree of dependence of the underlying observations when their pair-wise correlation is zero, and the relative expansion rates of N and T (the time dimension). In this respect, the method specifies the appropriate thresholding parameter to be used under Gaussian and non-Gaussian settings. The MT estimator of the sample correlation matrix is shown to be consistent in the spectral and Frobenius norms, and in terms of support recovery, so long as the true covariance matrix is sparse. The performance of the proposed MT estimator is compared to a number of other estimators in the literature using Monte Carlo experiments. It is shown that the MT estimator performs well and tends to outperform the other estimators, particularly when N is larger than T.
JEL Classifications: C13, C58.
Key Words: High-dimensional data, Multiple testing, Non-Gaussian observations, Sparsity, Thresholding, Shrinkage.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/BPS_14_September_2016.pdf
Supplementary Material: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/BPS_14_September_2016_Supplement.pdf
-
"Land Use Regulations, Migration and Rising House Price Dispersion in the U.S.", by Wukuang Cun and M. Hashem Pesaran. April 2018
Abstract: This paper develops a dynamic spatial equilibrium model of regional housing markets in which house prices are jointly determined with migration flows. Agents optimize period-by-period and decide whether to remain where they are or migrate to a new location at the start of each period. The gain from migration depends on the differences in incomes, housing and migration costs. The agents optimal location choice and the resultant migration process is shown to be Markovian with the transition probabilities across all location pairs given as non-linear functions of income and housing cost differentials, which are endogenously determined. On the supply side, in each location the construction rms build new houses by combing land and residential structures. The regional land supplies are exogenously given. When a tightening of regional land-use regulation reduces local housing supply, upward pressure on house prices created by excess housing demand cascades to other locations via migration. It is shown that the deterministic version of the model has a unique equilibrium and a unique balanced growth path. We estimate the state-level supplies of new residential land from the model using housing market and urban land acreage data. These estimates are shown to be signi cantly negatively correlated with the Wharton Residential Land Use Regulatory Index. The model can simultaneously account for the rise in house price dispersion and the interstate migration in the U.S. during the period 1976-2014. Counterfactual simulations suggest that reducing either land supply differentials or migration costs could signi cantly lower house price dispersion. The model predicts substantially smaller impacts of land-use deregulation on population reallocation as compared to recent existing models of housing and migration that assume population are perfectly mobile.
JEL Classifications: E0, R23, R31
Key Words: House price dispersion, endogenous location choice, interstate migration, land-use restriction, spatial equilibrium.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp18/PC_Spatial_House_Prices_Model_R_04_02_2018.pdf
-
"Posterior Means and Precisions of the Coefficients in Linear Models with Highly Collinear Regressors", by M. Hashem Pesaran and Ron P. Smith. November 2017, revised August 2018
Abstract: Exact collinearity between regressors makes their individual coefficients not identified. But, given an informative prior, their Bayesian posterior means are well defined. Just as exact collinearity causes non-identification of the parameters, high collinearity can be viewed as weak identification of the parameters, which is represented, in line with the weak instrument literature, by the correlation matrix being of full rank for a finite sample size T, but converging to a rank deficient matrix as T goes to infinity. This paper examines the asymptotic behaviour of the posterior mean and precision of the parameters of a linear regression model for both cases of exactly and highly collinear regressors. It shows that in both cases the posterior mean remains sensitive to the choice of prior means even if the sample size is sufficiently large, and that the posterior precision rises at a slower rate than the sample size. In the highly collinear case, the posterior means converge to normally distributed random variables whose mean and variance depend on the priors. A new recursively computed diagnostic statistic is proposed for detection of estimates that are subject to the high collinearity problem. Monte Carlo evidence is also provided to shed light on the small sample properties of the posterior means and precisions under different degrees of collinearity. The use of the diagnostic statistic is illustrated in an empirical application which estimates the effect of dividend yield on excess returns using Shiller's monthly data over the period 1872-2017.
JEL Classifications: C11, C18
Key Words: Bayesian identi cation, multicollinear regressions, weakly identi ed regression coefficients, highly collinear regressors.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp18/PS_high_collinearity_10_August_2018Ron.pdf
-
"Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes", by M. Hashem Pesarann and Ida Johnsson, forthcoming in Journal of Business and Economic Statistics, August 2018
Abstract: This paper proposes a new double-question survey whereby an individual is presented with two sets of questions; one on beliefs about current asset values and another on price expectations. A theoretical asset pricing model with heterogeneous agents is advanced and the existence of a negative relationship between price expectations and asset valuations is established, and is then tested using survey results on equity, gold and house prices. Leading indicators of bubbles and crashes are proposed and their potential value is illustrated in the context of a dynamic panel regression of realized house price changes across key Metropolitan Statistical Areas (MSAs) in the US. In an out-of-sample forecasting exercise it is also shown that forecasts of house price changes (pooled across MSAs) that make use of bubble and crash indicators perform signi ficantly better than a benchmark model that only uses lagged and expected house price changes.
JEL Classifications: C83, D84, G12, G14.
Key Words: Price expectations, bubbles and crashes, house prices, belief valuations.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp18/Double-Question-Survey-Pesaran-and-Johnsson-Manuscript-and-Online-Supplement-Aug-2018.pdf
Supplementary Materials: https://www.dropbox.com/s/qe2efuf4tge89gk/Supplementary%20Materials%20for%20Review.zip?dl=0
Data: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp18/DQ-survey-data-Aug-2012-Jan-2013.zip
Read Me: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp18/readme.txt
-
"Transformed Maximum Likelihood Estimation of Short Dynamic Panel Data Models with Interactive Effects", by Kazuhiko Hayakawa, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.06, May 2014
Abstract: This paper proposes the transformed maximum likelihood estimator for short dynamic panel data models with interactive fixed effects, and provides an extension of Hsiao et al. (2002) that allows for a multifactor error structure. This is an important extension since it retains the advantages of the transformed likelihood approach, whilst at the same time allows for observed factors (fixed or random). Small sample results obtained from Monte Carlo simulations show that the transformed ML estimator performs well in finite samples and outperforms the GMM estimators proposed in the literature in almost all cases considered.
JEL Classifications: C12, C13, C23.
Key Words: short T dynamic panels, transformed maximum likelihood, multi-factor error structure, interactive fixed effects.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp14/HPS_May14.pdf
-
"Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes", by M. Hashem Pesarann and Ida Johnsson, December 2016, revised June 2017
Abstract: This paper proposes a new double-question survey whereby an individual is presented with two sets of questions; one on beliefs about current asset values and another on price expectations. A theoretical asset pricing model with heterogeneous agents is advanced and the existence of a negative relationship between price expectations and asset valuations is established, which is tested using survey results on equity, gold and house prices. Leading indicators of bubbles and crashes are proposed and their potential value is illustrated in the context of a dynamic panel regression of realized house price changes across a number of key MSAs in the US.
JEL Classifications: C83, D84, G12, G14.
Key Words: Price expectations, bubbles and crashes, house prices, belief valuations.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/PJ-Double-Question-Survey-main-Paper-June-2017.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/PJ-Double-Question-Survey-Supplement-June-2017.pdf
Data: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/Double_Q_survey_data_Aug_2012-Jan_2013.zip
Replication: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/Double_Q_Survey_Replication.zip
-
"Posterior Means and Precisions of the Coefficients in Linear Models with Highly Collinear Regressors", by M. Hashem Pesaran and Ron P. Smith. November 2017
Abstract: When there is exact collinearity between regressors, their individual coefficients are not identi ed, but given an informative prior their Bayesian posterior means are well de ned. The case of high but not exact collinearity is more complicated but similar results follow. Just as exact collinearity causes non-identi cation of the parameters, high collinearity can be viewed as weak identi cation of the parameters, which we represent, in line with the weak instrument literature, by the correlation matrix being of full rank for a finite sample size T, but converging to a rank de cient matrix as T goes to infi nity. This paper examines the asymptotic behaviour of the posterior mean and precision of the parameters of a linear regression model for both the cases of exactly and highly collinear regressors. We show that in both cases the posterior mean remains sensitive to the choice of prior means even if the sample size is sufficiently large, and that the precision rises at a slower rate than the sample size. In the highly collinear case, the posterior means converge to normally distributed random variables whose mean and variance depend on the priors for coefficients and precision. The distribution degenerates to fixed points for either exact collinearity or strong identifi cation. The analysis also suggests a diagnostic statistic for the highly collinear case, which is illustrated with an empirical example.
JEL Classifications: C11, C18
Key Words: Bayesian identi cation, multicollinear regressions, weakly identi ed regression coefficients, highly collinear regressors.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/PS_high_collinearity_7_November_2017.pdf
-
"A One-Covariate at a Time, Multiple Testing Approach to Variable Selection in High-Dimensional Linear Regression Models", by Alexander Chudik, George Kapetanios and M. Hashem Pesaran, forthcoming in Econometrica, February 2018.
Abstract: This paper provides an alternative approach to penalised regression for model selection in the context of high dimensional linear regressions where the number of covariates is large, often much larger than the number of available bbservations. We consider the statistical significance of individual covariates one at a time, whilst taking full account of the multiple testing nature of the inferential problem involved. We refer to the proposed method as One Covariate at a Time Multiple Testing (OCMT) procedure, and use ideas from the multiple testing literature to control the probability of selecting the approximating model, the false positive rate and the false discovery rate. OCMT is easy to interpret, relates to classical statistical analysis, is valid under general assumptions, is faster to compute, and performs well in small samples. The usefulness of OCMT is also illustrated by an empirical application to forecasting U.S. output growth and inflation.
JEL Classifications: C52, C55
Key Words: One covariate at a time, multiple testing, model selection, high dimensionality, penalised regressions, boosting, Monte Carlo experiments.
Full Text: http://www.econ.cam.ac.uk/../mhp1/fp18/OCMTpaper_with_Theory_and_Emprical_Supplements.pdf
MC Supplement: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp18/MC_Supplement_OCMT_CPK_2018Feb23.pdf
-
"Estimation of Time-invariant Effects in Static Panel Data Models", by M. Hashem Pesaran and Qiankun Zhou, forthcoming in Econometrics Reviews, June 2016.
Abstract: This paper proposes the Fixed Effects Filtered (FEF) and Fixed Effects Filtered instrumental variable (FEF-IV) estimators for estimation and inference in the case of time-invariant effects in static panel data models when N is large and T is fixed. The FEF-IV allows for endogenous time-invariant regressors but assumes that there exists a suficient number of instruments for such regressors. It is shown that the FEF and FEF-IV estimators are [code]-consistent, and asymptotically normally distributed. The FEF estimator is compared with the Fixed Effects Vector Decomposition (FEVD) estimator proposed by Plumper and Troeger (2007) and conditions under which the two estimators are equivalent are established. It is also shown that the variance estimator proposed for FEVD estimator is inconsistent and its use could lead to misleading inference. Alternative variance estimators are proposed for both FEF and FEF-IV estimators which are shown to be consistent under fairly general conditions. The small sample properties of the FEF and FEF-IV estimators are investigated by Monte Carlo experiments, and it is shown that FEF has smaller bias and RMSE, unless an intercept is included in the second stage of the FEVD procedure which renders the FEF and FEVD estimators identical. The FEVD procedure, however, results in substantial size distortions since it uses incorrect standard errors. In the case where some of the time-invariant regressors are endogenous, the FEF-IV procedure is compared with a modified version of Hausman and Taylor (1981) (HT) estimator. It is shown that both estimators perform well and have similar small sample properties. But the application of standard HT procedure, that incorrectly assumes a sub-set of time-varying regressors are uncorrelated with the individual effects, will yield biased estimates and significant size distortions.
JEL Classifications: C01, C23, C33.
Key Words: Static panel data models, time-invariant effects, endogenous time-invariant regressors, Monte Carlo experiments, fixed effects filtered estimators.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp16/PesaranZhou_Time-invariant-estimation_June-11-2016.pdf
Supplementary Data: http://www.econ.cam.ac.uk/emeritus/mhp1/fp16/PesaranZhou_Time-invariant-estimation_May-27-2016_supplement.pdf
Stata Code and Instructions: http://qiankunzhou.weebly.com/research.html<
-
"A One-Covariate at a Time, Multiple Testing Approach to Variable Selection in High-Dimensional Linear Regression Models", by Alexander Chudik, George Kapetanios and M. Hashem Pesaran, February 2016, revised November 2016
Abstract: Model specification and selection are recurring themes in econometric analysis. Both topics become considerably more complicated in the case of large-dimensional data sets where the set of specification possibilities can become quite large. In the context of linear regression models, penalised regression has become the de facto benchmark technique used to trade off parsimony and fit when the number of possible covariates is large, often much larger than the number of available observations. However, issues such as the choice of a penalty function and tuning parameters associated with the use of penalized regressions remain contentious. In this paper, we provide an alternative approach that considers the statistical significance of the individual covariates one at a time, whilst taking full account of the multiple testing nature of the inferential problem involved. We refer to the proposed method as One Covariate at a Time Multiple Testing (OCMT) procedure. The OCMT provides an alternative to penalised regression methods: It is based on statistical inference and is therefore easier to interpret and relate to the classical statistical analysis, it allows working under more general assumptions, it is faster, and performs well in small samples for almost all of the different sets of experiments considered in this paper. We provide extensive theoretical and Monte Carlo results in support of adding the proposed OCMT model selection procedure to the toolbox of applied researchers. The usefulness of OCMT is also illustrated by an empirical application to forecasting U.S. output growth and inflation.
JEL Classifications: C52, C55
Key Words: One covariate at a time, multiple testing, model selection, high dimensionality, penalised regressions, boosting, Monte Carlo experiments.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/ChudikKapetaniosPesaran_14Nov2016.pdf
Supplement 1: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/Supplement_Theory_ChudikKapetaniosPesaran_10Nov2016.pdf
Supplement 2: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/Supplement_MC_ChudikKapetaniosPesaran_10Nov2016.pdf
-
"To Pool or not to Pool: Revisited", by M. Hashem Pesaran and Qiankun Zhou, forthcoming in Oxford Bulletin of Economics and Statistics, October 2017.
Abstract: This paper provides a new comparative analysis of pooled least squares and fixed effects estimators of the slope coefficients in the case of panel data models when the time dimension (T) is xed while the cross section dimension (N) is allowed to increase without bounds. The individual effects are allowed to be correlated with the regressors, and the comparison is carried out in terms of an exponent coefficients, δ, which measures the degree of pervasiveness of the fixed effects in the panel. The use of δ allows us to distinguish between poolability of small N dimensional panels with large T from large N dimensional panels with small T. It is shown that the pooled estimator remains consistent so long as δ < 1, and is asymptotically normally distributed if δ < 1/2, for a fixed T and as N → ∞. It is further shown that when δ < 1/2, the pooled estimator is more efficient than the fixed effects estimator. We also propose a Hausman type diagnostic test of δ < 1/2 as a simple test of poolability, and propose a pretest estimator that could be used in practice. Monte Carlo evidence supports the main theoretical findings and gives some indications of gains to be made from pooling when δ < 1/2.
JEL Classifications: C01, C23, C33
Key Words: Short panel, Fixed effects estimator, Pooled estimator, Efficiency.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp17/Pesaran-ZhouTo-pool-or-not-to-pool-Oct-2017.pdf
-
"Testing for Alpha in Linear Factor Pricing Models with a Large Number of Securities", by M. Hashem Pesaran and Takashi Yamagata, March 2017
Abstract: This paper proposes a novel test of zero pricing errors for the linear factor pricing model when the number of securities, N, can be large relative to the time dimension, T, of the return series. The test is based on Student t tests of individual securities and has a number of advantages over the existing standardised Wald type tests. It allows for non-Gaussianity and general forms of weakly cross correlated errors. It does not require estimation of an invertible error covariance matrix, it is much faster to implement, and is valid even if N is much larger than T. Monte Carlo evidence shows that the proposed test performs remarkably well even when T = 60 and N = 5, 000. The test is applied to monthly returns on securities in the S&P 500 at the end of each month in real time, using rolling windows of size 60. Statistically significant evidence against Sharpe-Lintner CAPM and Fama-French three factor models are found mainly during the recent financial crisis. Also we find a significant negative correlation between a twelve-months moving average p-values of the test and excess returns of long/short equity strategies (relative to the return on S&P 500) over the period November 1994 to June 2015, suggesting that abnormal profits are earned during episodes of market inefficiencies.
JEL Classifications: C12, C15, C23, G11, G12
Key Words: CAPM, Testing for alpha, Weak and spatial error cross-sectional dependence, S&P 500 securities, Long/short equity strategy.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/PY_LFPM_11_March_2017_Paper.pdf
Supplement: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/PY_LFPM_11_March_2017_Supplement.pdf
-
"Half-Panel Jackknife Fixed Effects Estimation of Panels with Weakly Exogenous Regressors", by Alexander Chudik, M. Hashem Pesarann and Jui-Chung Yang, SSRN Working Paper No. 281, September 2016
Abstract: This paper considers estimation and inference in fixed effects (FE) linear panel regression models with lagged dependent variables and/or other weakly exogenous (or predetermined) regressors when N (the cross section dimension) is large relative to T (the time series dimension). The paper first derives a general formula for the bias of the FE estimator which is a generalization of the Nickell type bias derived in the literature for the pure dynamic panel data models. It shows that in the presence of weakly exogenous regressors, inference based on the FE estimator will result in size distortions unless N/T is suffciently small. To deal with the bias and size distortion of FE estimator when N is large relative to T, the use of half-panel Jackknife FE estimator is proposed and its asymptotic distribution is derived. It is shown that the bias of the proposed estimator is of order [code], and for valid inference it is only required that N/T[code], as N, T [code] jointly. Extensions to panel data models with time effects (TE), for balanced as well as unbalanced panels, are also provided. The theoretical results are illustrated with Monte Carlo evidence. It is shown that the FE estimator can suffer from large size distortions when N > T, with the proposed estimator showing little size distortions. The use of half-panel jackknife FE-TE estimator is illustrated with two empirical applications from the literature.
JEL Classifications: C32, E17, E32, F44, F47, O51, Q43.
Key Words: Panel Data Models, Weakly Exogenous Regressors, Lagged Dependent Variable, Fixed Effects, Time Effects, Unbalanced Panels, Half-Panel Jackknife, Bias Correction
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/CPY_jackknifeFE_13-Sep-2016.pdf
Supplement: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/CPY_jackknifeFE_supplement_12-Sep-2016.pdf
Data: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/Matlab-Codes-and-Data-for-Chudik-Pesaran-and-Yang-(2016).rar
-
"Counterfactual Analysis in Macroeconometrics: An Empirical Investigation into the Effects of Quantitative Easing", by M. Hashem Pesaran and Ron P Smith, IZA Discussion Paper No. 6618, May 2012, revised June 2014
Abstract: The policy innovations that followed the recent Great Recession, such as unconventional monetary policies, prompted renewed interest in the question of how to measure the effectiveness of such policy interventions. To test policy effectiveness requires a model to construct a counterfactual for the outcome variable in the absence of the policy intervention and a way to determine whether the differences between the realised outcome and the model-based counter- factual outcomes are larger than what could have occurred by chance in the absence of policy intervention. Pesaran & Smith (2014b) propose tests of policy ineffectiveness in the context of macroeconometric rational expectations dynamic stochastic general equilibrium models. When we are certain of the specification, estimation of the complete system imposing all the cross-equation restrictions implied by the full structural model is more efficient. But if the full model is misspecified, one may obtain more reliable estimates of the counterfactul outcomes from a parsimonious reduced form policy response equation, which conditions on lagged values, and on the policy measures and variables known to be invariant to the policy intervention. We propose policy ineffectiveness tests based on such reduced forms and illustrate the tests with an application to the unconventional monetary policy known as quantitative easing (QE) adopted in the UK.
JEL Classifications: C18, C54, E65
Key Words: Counterfactuals, policy analysis, policy ineffectiveness test, macroeconomics, quantitative easing (QE)
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp14/PS-on-CF_17-June-2014.pdf
-
"Oil Prices and the Global Economy: Is It Different This Time Around?", by Kamiar Mohaddes and M. Hashem Pesarann, July 2016
Abstract: The recent plunge in oil prices has brought into question the generally accepted view that lower oil prices are good for the US and the global economy. In this paper, using a quarterly multi-country econometric model, we first show that a fall in oil prices tends relatively quickly to lower interest rates and inflation in most countries, and increase global real equity prices. The effects on real output are positive, although they take longer to materialize (around 4 quarters after the shock). We then re-examine the effects of low oil prices on the US economy over different sub-periods using monthly observations on real oil prices, real equity prices and real dividends. We confirm the perverse positive relationship between oil and equity prices over the period since the 2008 financial crisis highlighted in the recent literature, but show that this relationship has been unstable when considered over the longer time period of 1946-2016. In contrast, we find a stable negative relationship between oil prices and real dividends which we argue is a better proxy for economic activity (as compared to equity prices). On the supply side, the effects of lower oil prices differ widely across the different oil producers, and could be perverse initially, as some of the major oil producers try to compensate their loss of revenues by raising production. Taking demand and supply adjustments to oil price changes as a whole, we conclude that oil markets equilibrate but rather slowly, with large episodic swings between low and high oil prices.
JEL Classifications: C32, E17, E32, F44, F47, O51, Q43.
Key Words: Oil prices, equity prices, dividends, economic growth, oil supply, global oil markets, and international business cycle.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/MP_Oil_Prices_&_Global_Economy_160703.pdf
-
"Tests of Policy Ineffectiveness in Macroeconometrics", by M. Hashem Pesaran and Ron P. Smith, CAFE Research Paper No. 14.07, June 2014, revised January 2015
Abstract: This paper considers tests of the null hypothesis of the ineffectiveness of a policy intervention, defined as a change in the parameters of a policy rule, in the context of a macroeconometric dynamic stochastic general equilibrium (DSGE) model. This is an ex post evaluation of an intervention in a single country, where data are available before and after the interven- tion. The tests are based on the difference between the realisations of the outcome variable of interest and counterfactuals based on no policy intervention, using only the pre-intervention parameter estimates, and in consequence the Lucas Critique does not apply. We show that such tests will have power to detect the effect of a policy intervention on a target outcome variable that changes the steady state value of that variable, e.g. the target inflation rate. They will have less power against interventions which do not change the steady state, since these typically only have transitory effects. Asymptotic distributions of the proposed tests are derived both when the post intervention sample is fixed as the pre-intervention sample expands, and when both samples rise jointly but at different rates. The performance of the test is illustrated by a simulated policy analysis of a three equation New Keynesian Model.
JEL Classifications: C18, C54, E65.
Key Words: Counterfactuals, policy analysis, policy ineffectiveness test, macroeconomics.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/PS-on-PI_16-January-2015.pdf
-
"To Pool or not to Pool: Revisited", by M. Hashem Pesaran and Qiankun Zhou, June 2015
Abstract: This paper provides a new comparative analysis of pooled least squares and fixed effects estimators of the slope coefficients in the case of panel data models when the time dimension (T) is fixed while the cross section dimension (N) is allowed to increase without bounds. The individual effects are allowed to be correlated with the regressors, and the comparison is carried out in terms of an exponent coefficient, δ, which measures the degree of pervasiveness of the fixed effects in the panel. It is shown that the pooled estimator remains consistent so long as δ < 1, and is asymptotically normally distributed if δ < 1/2, for a fixed T and as N → ∞. It is further shown that when δ < 1/2, the pooled estimator is more efficient than the fixed effects estimator. Monte Carlo evidence provided supports the main theoretical findings and gives some indications of gains to be made from pooling when δ < 1/2. The problem of how to estimate δ in short T panels is not considered in this paper.
JEL Classifications: C01, C23, C33
Key Words: Short panel, Fixed effects estimator, Pooled estimator, Efficiency.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/Pesaran-&-ZhouTo-pool-or-not-to-pool_revisited_June-15-2015.pdf
-
"A Two Stage Approach to Spatio-Temporal Analysis with Strong and Weak Cross-Sectional Dependence", by Natalia Bailey, Sean Holly, and M. HashemPesaran, CESifo Working Paper No. 4592, forthcoming in the Journal of Applied Econometrics, January 2015.
Abstract: An understanding of the spatial dimension of economic and social activity requires methods that can separate out the relationship between spatial units that is due to the effect of common factors from that which is purely spatial even in an abstract sense. The same applies to the empirical analysis of networks in general. We use cross unit averages to extract common factors (viewed as a source of strong cross-sectional dependence) and compare the results with the principal components approach widely used in the literature. We then apply multiple testing procedures to the de-factored observations in order to determine significant bilateral correlations (signifying connections) between spatial units and compare this to an approach that just uses distance to determine units that are neighbours. We apply these methods to real house price changes at the level of Metropolitan Statistical Areas in the USA, and estimate a heterogeneous spatio-temporal model for the de-factored real house price changes and obtain significant evidence of spatial connections, both positive and negative.
JEL Classifications: C21, C23
Key Words: Spatial and factor dependence, spatio-temporal models, positive and negative connections, house price changes.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp14/bhp_Dec_16_2014_JAE.pdf
-
"A multi-country approach to forecasting output growth using PMIs", by Alexander Chudik, Valerie Grossmanz and M. Hashem Pesaran, forthcoming in the Journal of Econometrics, January 2016.
Abstract: This paper derives new theoretical results for forecasting with Global VAR (GVAR) models. It is shown that the presence of a strong unobserved common factor can lead to an undetermined GVAR model. To solve this problem, we propose augmenting the GVAR with additional proxy equations for the strong factors and establish conditions under which forecasts from the augmented GVAR model (AugGVAR) uniformly converge in probability (as the panel dimensions N,T [code] ∞ such that N/T → k for some 0 < k < ∞) to the infeasible optimal forecasts obtained from a factor-augmented high-dimensional VAR model. The small sample properties of the proposed solution are investigated by Monte Carlo experiments as well as empirically. In the empirical part, we investigate the value of the information content of Purchasing Managers Indices (PMIs) for forecasting global (48 countries) growth, and compare forecasts from Aug- GVAR models with a number of data-rich forecasting methods, including Lasso, Ridge, partial least squares and factor-based methods. It is found that (a) regardless of the forecasting meth- ods considered, PMIs are useful for nowcasting, but their value added diminishes quite rapidly with the forecast horizon, and (b) AugGVAR forecasts do as well as other data-rich forecasting techniques for short horizons, and tend to do better for longer forecast horizons.
JEL Classifications: C53, E37.
Key Words: Global VARs, High-dimensional VARs, Augmented GVAR, Forecasting, Nowcasting, Data-rich methods, GDP and PMIs
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp16/CGP_GDPnowcasting_10-November-2014.pdf
-
"Exponent of Cross-sectional Dependence: Estimation and Inference", by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, forthcoming in the Journal of Applied Econometrics, January 2015.
Abstract: In this paper, we provide a characterisation of the degree of cross-sectional dependence in a two dimensional array, [code] in terms of the rate at which the variance of the cross-sectional average of the observed data varies with N. We show that under certain conditions this is equivalent to the rate at which the largest eigenvalue of the covariance matrix of [code] rises with N. We represent the degree of cross-sectional dependence by
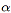 , defined by the standard deviation, [code], where [code] is a simple cross-sectional average of [code]. We refer to as the `exponent of crosssectional dependence', and show how it can be consistently estimated for values of > 1/2. We propose bias corrected estimators, derive their asymptotic properties and consider a number of extensions. We include a detailed Monte Carlo simulation study supporting the theoretical results. We also provide a number of empirical applications investigating the degree of inter-linkages of real and financial variables in the global economy, the extent to which macroeconomic variables are interconnected across and within countries, and present recursive estimates of applied to excess returns on securities included in the Standard & Poor 500 index.
, defined by the standard deviation, [code], where [code] is a simple cross-sectional average of [code]. We refer to as the `exponent of crosssectional dependence', and show how it can be consistently estimated for values of > 1/2. We propose bias corrected estimators, derive their asymptotic properties and consider a number of extensions. We include a detailed Monte Carlo simulation study supporting the theoretical results. We also provide a number of empirical applications investigating the degree of inter-linkages of real and financial variables in the global economy, the extent to which macroeconomic variables are interconnected across and within countries, and present recursive estimates of applied to excess returns on securities included in the Standard & Poor 500 index.
JEL Classifications: C21, C32
Key Words: Cross correlations, Cross-sectional dependence, Cross-sectional averages, Weak and strong factor models
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp15/BKP_26_Jan_2015.pdf
Supplementary Appendices: http://www.econ.cam.ac.uk/emeritus/mhp1/fp15/BKP_exponent_supplement_26_Jan_2015.pdf
Codes and Data: http://www.econ.cam.ac.uk/emeritus/mhp1/fp15/BKP_GAUSS_procedures.zip
-
"Is There a Debt-threshold Effect on Output Growth?", by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, and Mehdi Raissi, forthcoming in the Review of Economics and Statistics, November 2015. Abstract: This paper studies the long-run impact of public debt expansion on economic growth and investigates whether the debt-growth relation varies with the level of indebtedness. Our contribution is both theoretical and empirical. On the theoretical side, we develop tests for threshold effects in the context of dynamic heterogeneous panel data models with cross-sectionally dependent errors and illustrate, by means of Monte Carlo experiments, that they perform well in small samples. On the empirical side, using data on a sample of 40 countries (grouped into advanced and developing) over the 1965-2010 period, we find no evidence for a universally applicable threshold effect in the relationship between public debt and economic growth, once we account for the impact of global factors and their spillover effects. Regardless of the threshold, however, we find significant negative long-run effects of public debt build-up on output growth. Provided that public debt is on a downward trajectory, a country with a high level of debt can grow just as fast as its peers.
JEL Classifications: C23, E62, F34, H6
Key Words: Panel tests of threshold effects, long-run relationships, estimation and inference, large dynamic heterogeneous panels, cross-section dependence, debt, and inflation.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp16/CMPR_July3-2015_2-(uploaded-REStat).pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/fp16/Supplement_03July2015_3-(upload-REStat).pdf
Matlab Codes for the CS-DL Estimators: http://www.econ.cam.ac.uk/people-files/cto/km418/CMPR_CSDL.zip
Matlab Codes for Panel Tests of Threshold Effects: http://www.econ.cam.ac.uk/people-files/cto/km418/CMPR_Threshold_Codes.zip
-
"Econometric Analysis of Production Networks with Dominant Units", by M. Hashem Pesarann and Cynthia Fan Yang, USC Dornsife Working Paper No. 16-25, October 2016
Abstract: This paper builds on the work of Acemoglu et al. (2012) and considers a production network with unobserved common technological factor and establishes general conditions under which the network structure contributes to aggregate fluctuations. It introduces the notions of strongly and weakly dominant units, and shows that at most a finite number of units in the network can be strongly dominant, while the number of weakly dominant units can rise with N (the cross section dimension). This paper further establishes the equivalence between the highest degree of dominance in a network and the inverse of the shape parameter of the power law. A new extremum estimator for the degree of pervasiveness of individual units in the network is proposed, and is shown to be robust to the choice of the underlying distribution. Using Monte Carlo techniques, the proposed estimator is shown to have satisfactory small sample properties. Empirical applications to US input-output tables suggest the presence of production sectors with a high degree of pervasiveness, but their effects are not sufficiently pervasive to be considered as strongly dominant.
JEL Classifications: C12, C13, C23, C67, E32.
Key Words: Aggregate fluctuations, strongly and weakly dominant units, spatial models, outdegrees, degree of pervasiveness, power law, input-output tables, US economy
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/Pesaran_and_Yang_analysis_of_networks_October_2016_SSRN-id2851148.pdf
-
"An Exponential Class of Dynamic Binary Choice Panel Data Models with Fixed Effects", by Majid M. Al-Sadoon, Tong Li and M. Hashem Pesaran, CESifo Working Paper No. 4033, forthcoming in Econometrics Reviews, August 2016.
Abstract: This paper proposes an exponential class of dynamic binary choice panel data models for the analysis of short T (time dimension) large N (cross section dimension) panel data sets that allows for unobserved heterogeneity (fixed effects) to be arbitrarily correlated with the covariates. The paper derives moment conditions that are in- variant to the fixed effects which are then used to identify and estimate the parameters of the model. Accordingly, GMM estimators are proposed that are consistent and asymptotically normally distributed at the root-N rate. We also study the conditional likelihood approach, and show that under exponential specification it can identify the effect of state dependence but not the effects of other covariates. Monte Carlo experiments show satisfactory nite sample performance for the proposed estimators, and investigate their robustness to miss-specification.
JEL Classifications: C23, C25
Key Words: Dynamic Discrete Choice, Fixed Effects, Panel Data, GMM, CMLE.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp16/Al-Sadoon-Li-and-Pesaran-DBC-28-August-2016.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/fp16/Supplement-to-Al-Sadoon-Li-and-Pesaran-DBC-APE_probit-MC-experiments-r.pdf
-
"Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes", by M. Hashem Pesarann and Ida Johnsson, December 2016, revised May 2017
Abstract: This paper proposes a new double-question survey whereby an individual is presented with two sets of questions; one on beliefs about current asset values and another on price expectations. A theoretical asset pricing model with heterogeneous agents is advanced and the existence of a negative relationship between price expectations and asset valuations is established, which is tested using survey results on equity, gold and house prices. Leading indicators of bubbles and crashes are proposed and their potential value is illustrated in the context of a dynamic panel regression of realized house price changes across a number of key MSAs in the US.
JEL Classifications: C83, D84, G12, G14.
Key Words: Price expectations, bubbles and crashes, house prices, belief valuations.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/PJ-Double-Question-Survey-Paper-28-May-2017-(main-paper).pdf
Suppliment: http://www.econ.cam.ac.uk/emeritus/mhp1/wp17/PJ-Double-Question-Survey-Paper-28-May-2017-(Supplement).pdf
Data: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/Double_Q_survey_data_Aug_2012-Jan_2013.zip
Replication: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/Double_Q_Survey_Replication.zip
-
"Oil Prices and the Global Economy: Is It Different This Time Around?", by Kamiar Mohaddes and M. Hashem Pesaran, July 2016
Abstract: The recent plunge in oil prices has brought into question the generally accepted view that lower oil prices are good for the US and the global economy. In this paper, using a quarterly multi-country econometric model, we first show that a fall in oil prices tends relatively quickly to lower interest rates and inflation in most countries, and increase global real equity prices. The effects on real output are positive, although they take longer to materialize (around 4 quarters after the shock). We then re-examine the effects of low oil prices on the US economy over different sub-periods using monthly observations on real oil prices, real equity prices and real dividends. We confirm the perverse positive relationship between oil and equity prices over the period since the 2008 financial crisis highlighted in the recent literature, but show that this relationship has been unstable when considered over the longer time period of 1946-2016. In contrast, we find a stable negative relationship between oil prices and real dividends which we argue is a better proxy for economic activity (as compared to equity prices). On the supply side, the effects of lower oil prices differ widely across the different oil producers, and could be perverse initially, as some of the major oil producers try to compensate their loss of revenues by raising production. Taking demand and supply adjustments to oil price changes as a whole, we conclude that oil markets equilibrate but rather slowly, with large episodic swings between low and high oil prices.
JEL Classifications: C32, E17, E32, F44, F47, O51, Q43.
Key Words: Oil prices, equity prices, dividends, economic growth, oil supply, global oil markets, and international business cycle.
Full Text:http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/MP_Oil_Prices_&_Global_Economy_160703.pdf
-
"Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes", by M. Hashem Pesaran and Ida Johnsson, December 2016, revised January 2017
Abstract: This paper proposes a new double-question survey whereby an individual is presented with two sets of questions; one on beliefs about current asset values and another on price expectations. A theoretical asset pricing model with heterogeneous agents is advanced and the existence of a negative relationship between price expectations and asset valuations is established, which is tested using survey results on equity, gold and house prices. Leading indicators of bubbles and crashes are proposed and their potential value is illustrated in the context of a dynamic panel regression of realized house price changes across a number of key MSAs in the US.
JEL Classifications: C83, D84, G12, G14.
Key Words: Price expectations, bubbles and crashes, house prices, belief valuations.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/Pesaran_and_Johnsson_Double-question_2_January_2017.pdf
Suppliment: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/PJ_Double_Q_Supplement_2_January_2017.pdf
Data: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/Double_Q_survey_data_Aug_2012-Jan_2013.zip
Replication: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp17/Double_Q_Survey_Replication.zip
-
"Double-question Survey Measures for the Analysis of Financial Bubbles and Crashes", by M. Hashem Pesaran and Ida Johnsson, December 2016
Abstract: This paper proposes a new double-question survey method that elicits information about how individuals subjective belief valuations are compared and related to their price expectations. An individual respondent is presented with two sets of questions, one that asks about his/her belief regarding the value of an asset (whether it is over- or under-valued), and another regarding his/her expectations of the future price of that asset. Responses to these two questions are then used to measure the extent to which prices are likely to move towards or away from the subjectively perceived fundamental values. Using a theoretical asset pricing model with heterogenous agents we show that there exists a negative relationship between the agents expectations of price changes and their asset valuation. Double question surveys on equity, gold and house prices provide evidence in support of such relationships, particularly in the case of house price expectations. The effects of demographic factors, such as sex, age, education, ethnicity, and income are also investigated. It is shown that for house price expectations such demographic factors cease to be statistically significant once we condition on the respondents' location and their asset valuation indicator. The results of the double-question surveys are then used to construct leading bubble and crash indicators, and their potential value is illustrated in the context of a dynamic panel regression of realized house price changes across a number of key Metropolitan Statistical Areas in the US.
JEL Classifications: C83, D84, G12, G14.
Key Words: Price expectations, bubbles and crashes, house prices, belief valuations.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/Pesaran_and_Johnsson_Double_Question_Surveys_Dec_2016_SSRN-id2880856.pdf
-
"Big Data Analytics: A New Perspective", by Alexander Chudik, George Kapetanios and M. Hashem Pesaran, February 2016
Abstract: Model specification and selection are recurring themes in econometric analysis. Both topics become considerably more complicated in the case of large-dimensional data sets where the set of specification possibilities can become quite large. In the context of linear regression models, penalised regression has become the de facto benchmark technique used to trade off parsimony and fit when the number of possible covariates is large, often much larger than the number of available observations. However, issues such as the choice of a penalty function and tuning parameters associated with the use of penalized regressions remain contentious. In this paper, we provide an alternative approach that considers the statistical significance of the individual covariates one at a time, whilst taking full account of the multiple testing nature of the inferential problem involved. We refer to the proposed method as One Covariate at a Time Multiple Testing (OCMT) procedure The OCMT has a number of advantages over the penalised regression methods: It is based on statistical inference and is therefore easier to interpret and relate to the classical statistical analysis, it allows working under more general assumptions, it is computationally simple and considerably faster, and it performs better in small samples for almost all of the five different sets of experiments considered in this paper. Despite its simplicity, the theory behind the proposed approach is quite complicated. We provide extensive theoretical and Monte Carlo results in support of adding the proposed OCMT model selection procedure to the toolbox of applied researchers.
JEL Classifications: C52, C55
Key Words: One covariate at a time, multiple testing, model selection, high dimensionality, penalised regressions, boosting, Monte Carlo experiments.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/ChudikKapetaniosPesaran_BDA_11Feb2016_main.pdf
Supplement 1: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/TheorySupplement_to_ChudikKapetaniosPesaran_BDA_11Feb2016.pdf
Supplement 2: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/MC_Supplement_to_ChudikKapetaniosPesaran_BDA_05Feb2016.pdf
-
"Country-Specific Oil Supply Shocks and the Global Economy: A Counterfactual Analysis", by Kamiar Mohaddes and M. Hashem Pesaran, forthcoming in Energy Economics, July 2016.
Abstract: This paper investigates the global macroeconomic consequences of country-specific oil-supply shocks. Our contribution is both theoretical and empirical. On the theo- retical side, we develop a model for the global oil market and integrate this within a compact quarterly model of the global economy to illustrate how our multi-country approach to modelling oil markets can be used to identify country-specific oil-supply shocks. On the empirical side, estimating the GVAR-Oil model for 27 countries/regions over the period 1979Q2 to 2013Q1, we show that the global economic implications of oil-supply shocks (due to, for instance, sanctions, wars, or natural disasters) vary considerably depending on which country is subject to the shock. In particular, we find that adverse shocks to Iranian oil output are neutralized in terms of their effects on the global economy (real outputs and financial markets) mainly due to an increase in Saudi Arabian oil production. In contrast, a negative shock to oil supply in Saudi Arabia leads to an immediate and permanent increase in oil prices, given that the loss in Saudi Arabian production is not compensated for by the other oil producers. As a result, a Saudi Arabian oil supply shock has significant adverse effects for the global economy with real GDP falling in both advanced and emerging economies, and large losses in real equity prices worldwide.
JEL Classifications: C32, E17, F44, F47, O53, Q43.
Key Words: Country-specific oil supply shocks, identification of shocks, oil sanctions, oil prices, global oil markets, Iran, Saudi Arabia, international business cycle, Global VAR (GVAR), interconnectedness, impulse responses.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp16/MP_GVAR_July-2015-EE.pdf
Data: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp16/MP_GVAR_Data.zip
-
"Country-Specific Oil Supply Shocks and the Global Economy: A Counterfactual Analysis", by Kamiar Mohaddes and M. Hashem Pesaran, May 2015
Abstract: This paper investigates the global macroeconomic consequences of country-specific oil-supply shocks. Our contribution is both theoretical and empirical. On the theoretical side, we develop a model for the global oil market and integrate this within a compact quarterly model of the global economy to illustrate how our multi-country approach to modelling oil markets can be used to identify country-specific oil-supply shocks. On the empirical side, estimating the GVAR-Oil model for 27 countries/regions over the period 1979Q2 to 2013Q1, we show that the global economic implications of oil-supply shocks (due to, for instance, sanctions, wars, or natural disasters) vary considerably depending on which country is subject to the shock. In particular, we find that adverse shocks to Iranian oil output are neutralized in terms of their effects on the global economy (real outputs and financial markets) mainly due to an increase in Saudi Arabian oil production. In contrast, a negative shock to oil supply in Saudi Arabia leads to an immediate and permanent increase in oil prices, given that the loss in Saudi Arabian production is not compensated for by the other oil producers. As a result, a Saudi Arabian oil supply shock has significant adverse effects for the global economy with real GDP falling in both advanced and emerging economies, and large losses in real equity prices worldwide.
JEL Classifications: C32, E17, F44, F47, O53, Q43.
Key Words: Country-specific oil supply shocks, identification of shocks, oil sanctions, oil prices, global oil markets, Iran, Saudi Arabia, international business cycle, Global VAR (GVAR), interconnectedness, impulse responses.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/MP_GVAR_20_June_2015.pdf
-
"A Multiple Testing Approach to the Regularisation of Large Sample Correlation Matrices", by Natalia Bailey, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.05, May 2014, revised November 2015
Abstract: This paper proposes a regularisation method for the estimation of large covariance matrices that uses insights from the multiple testing (MT) literature. The approach tests the statistical significance of individual pair-wise correlations and sets to zero those elements that are not statistically significant, taking account of the multiple testing nature of the problem. By using the inverse of the normal distribution at a predetermined significance level, it circumvents the challenge of estimating the theoretical constant arising in the rate of convergence of existing thresholding estimators, and hence it is easy to implement and does not require cross-validation. The MT estimator of the sample correlation matrix is shown to be consistent in the spectral and Frobenius norms, and in terms of support recovery, so long as the true covariance matrix is sparse. The performance of the proposed MT estimator is compared to a number of other estimators in the literature using Monte Carlo experiments. It is shown that the MT estimator performs well and tends to outperform the other estimators, particularly when the cross section dimension, N, is larger than the time series dimension, T.
JEL Classifications: C13, C58.
Key Words: Sparse correlation matrices, High-dimensional data, Multiple testing, Thresholding, Shrinkage.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/BPS_5-Nove-2015.pdf
Supplementary Material: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/BPS_Supplement_5-November-2015.pdf
-
"An Exponential Class of Dynamic Binary Choice Panel Data Models with Fixed Effects", by Majid M. Al-Sadoon, Tong Li and M. Hashem Pesaran, CESifo Working Paper No. 4033, October 2012, revised January 2016
Abstract: This paper proposes an exponential class of dynamic binary choice panel data models for the analysis of short T( time dimension) large N (cross section dimension) panel data sets that allows for unobserved heterogeneity (fixed effects) to be arbitrarily correlated with the covariates. The paper derives moment conditions that are in- variant to the fixed effects which are then used to identify and estimate the parameters of the model. Accordingly, GMM estimators are proposed that are consistent and asymptotically normally distributed at the root-N rate. We also study the conditional likelihood approach, and show that under exponential specification it can identify the effect of state dependence but not the effects of other covariates. Monte Carlo experiments show satisfactory nite sample performance for the proposed estimators, and investigate their robustness to miss-specification..
JEL Classifications: C23, C25
Key Words: Dynamic Discrete Choice, Fixed Effects, Panel Data, GMM, CMLE.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp16/AlSaddonTongPesaran-Jan-2016.pdf
-
"Estimation of Time-invariant Effects in Static Panel Data Models", by M. Hashem Pesaran and Qiankun Zhou, January 2015
Abstract: This paper proposes the Fixed Effects Filtered (FEF) and Fixed Effects Filtered instrumental variable (FEF-IV) estimators for estimation and inference in the case of time-invariant effects in static panel data models when N is large and T is fixed. It is shown that the FEF and FEF-IV estimators are pN-consistent, and asymptotically normally distributed. The FEF estimator is compared with the Fixed Effects Vector Decomposition (FEVD) estimator proposed by Plumper and Troeger (2007) and conditions under which the two estimators are equivalent are established. It is also shown that the variance estimator proposed for FEVD estimator is inconsistent and its use could lead to misleading inference. Alternative variance estimators are proposed for both FEF and FEF-IV estimators which are shown to be consistent under fairly general conditions. The small sample properties of the FEF and FEF-IV estimators are investigated by Monte Carlo experiments, and it is shown that FEF has smaller bias and RMSE, unless an intercept is included in the second stage of the FEVD procedure which renders the FEF and FEVD estimators identical. The FEVD procedure, however, results in substantial size distortions since it uses incorrect standard errors. We also compare the FEF-IV estimator with the estimator proposed by Hausman and Taylor (1981), when one of the time-invariant regressors is correlated with the fixed effects. Both FEF and FEF-IV estimators are shown to be robust to error variance heteroskedasticity and residual serial correlation.
JEL Classifications: C01, C23, C33.
Key Words: Static panel data models, Time-invariant effects, Fixed Effects Filtered estimator, Fixed Effects Filtered instrumental variables estimator.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/PesaranZhou_Time-invariant-estimation_Sep-5-2014.pdf
-
"Long-Run Effects in Large Heterogenous Panel Data Models with Cross-Sectionally Correlated Errors", by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran and Mehdi Raissi, forthcoming in Advances in Econometrics, V36 Essays in Honor of Aman Ullah, 2016.
Abstract: This paper develops a cross-sectionally augmented distributed lag (CS-DL) approach to the estimation of long-run effects in large dynamic heterogeneous panel data models with cross-sectionally dependent errors. The asymptotic distribution of the CS-DL estimator is derived under coeficient heterogeneity in the case where the time dimension (T) and the cross-section dimension (N) are both large. The CS-DL approach is compared with more standard panel data estimators that are based on autoregressive distributed lag (ARDL) specifications. It is shown that unlike the ARDL type estimator, the CS-DL estimator is robust to misspecification of dynamics and error serial correlation. The theoretical results are illustrated with small sample evidence obtained by means of Monte Carlo simulations, which suggest that the performance of the CS-DL approach is often superior to the alternative panel ARDL estimates, particularly when T is not too large and lies in the range of 30 to 50.
JEL Classifications: C23.
Key Words: Long-run relationships, estimation and inference, panel distributed lags, large dynamic heterogeneous panels, cross-section dependence.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/fp16/CS-DL_30-October-2015.pdf
-
"Theory and Practice of GVAR Modeling", by Alexander Chudik, and M. Hashem Pesaran, SSRN Research Paper Series No. 14.04, forthcoming in the Journal of Economic Surveys, September 2014.
Abstract: The Global Vector Autoregressive (GVAR) approach has proven to be a very useful approach to analyze interactions in the global macroeconomy and other data networks where both the cross-section and the time dimensions are large. This paper surveys the latest developments in the GVAR modeling, examining both the theoretical foundations of the approach and its numerous empirical applications. We provide a synthesis of existing literature and highlight areas for future research.
JEL Classifications: C32, E17.
Key Words: Global VAR, global macroeconometric modelling, global interdependencies, policy simulations.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp14/CP-GVAR-Surveys-Sept2014.pdf
-
"Business Cycle Effects of Credit and Technology Shocks in a DSGE Model with Firm Default", by M. Hashem Pesaran and TengTeng Xu, CWPE Working paper. No. 1159, CESifo Working Paper No. 3609, IZA Discussion Paper No. 6027, October 2011, under revision
Abstract: This paper proposes a theoretical framework to analyze the relationship between credit shocks, firms defaults and volatility, and to study the impact of credit shocks on business cycle dynamics. Firms are identical ex ante but differ ex post due to different realizations of firm specific technology shocks, possibly leading to default by some firms. The paper advances a new modelling approach for the analysis of firm defaults and financial intermediation that takes account of the financial implications of such defaults for both households and banks. Results from a calibrated version of the model suggest that, in the steady state, firm's default probability rises with firm's leverage ratio, and the level of uncertainties in the economy. A positive credit shock, defined as a rise in the loan to deposit ratio, increases output, consumption, hours and productivity, and reduces the spread between loan and deposit rates. The effects of the credit shock tend to be highly persistent even without price rigidities and habit persistence in consumption behaviour.
JEL Classifications: E32, E44, G21.
Key Words: Bank Credit, Financial Intermediation, Firm Heterogeneity and Defaults, Interest Rate Spread, Real Financial Linkages.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/MacroCredit_PesaranXu-Feb-2013.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/MacroCredit_ 5Oct2011_Supplement.pdf
-
"An Exponential Class of Dynamic Binary Choice Panel Data Models with Fixed Effects", by Majid M. Al-Sadoon, Tong Li and M. Hashem Pesaran, CESifo Working Paper No. 4033, October 2012, revised August 2014
Abstract: This paper develops a model for dynamic binary choice panel data that allows for unobserved heterogeneity to be arbitrarily correlated with covariates. The model is of the exponential type. We derive moment conditions that enable us to eliminate the unobserved heterogeneity term and at the same time to identify the parameters of the model. We then propose GMM estimators that are consistent and asymptotically normally distributed at the root-N rate. We also study the conditional likelihood approach, which can only identify the effect of state dependence in our case. Monte Carlo experiments demonstrate the finite sample performance of our estimators.
JEL Classifications: C23, C25
Key Words: Dynamic Discrete Choice, Fixed Effects, Panel Data, GMM, CMLE.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/DBC-August-14.pdf
-
"Robust Standard Errors in Transformed Likelihood Estimation of Dynamic Panel Data Models with Cross-Sectional Heteroskedasticity", by Kazuhiko Hayakawa and M. Hashem Pesaran, CWPE Working Paper No. 1224, IZA Discussion Paper 6583, Cesifo Working Paper No.3850, forthcoming in Journal of Econometrics, March 2015.
Abstract: This paper extends the transformed maximum likelihood approach for estimation of dynamic panel data models by Hsiao, Pesaran, and Tahmiscioglu (2002) to the case where the errors are cross-sectionally heteroskedastic. This extension is not trivial due to the incidental parameters problem and its implications for estimation and inference. We approach the problem by working with a mis-specified homoskedastic model, and then show that the transformed maximum likelihood estimator continues to be consistent even in the presence of cross-sectional heteroskedasticity. We also obtain standard errors that are robust to cross-sectional heteroskedasticity of unknown form. By means of Monte Carlo simulations, we investigate the finite sample behavior of the transformed maximum likelihood estimator and compare it with various GMM estimators proposed in the literature. Simulation results reveal that, in terms of median absolute errors and accuracy of inference, the transformed likelihood estimator outperforms the GMM estimators in almost all cases.
JEL Classifications: C12, C13, C23
Key Words: Dynamic Panels, Cross-sectional heteroskedasticity, Monte Carlo simulation, Transformed MLE, GMM estimation.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp15/Hayakawa_Pesaran_robustML_R2_04Nov2014.pdf
Matlab Code: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/Matlab-code-and-data-for-TransML-Hayakawa-and-Pesaran-2012.zip
Supplementary Data: http://www.econ.cam.ac.uk/emeritus/mhp1/fp15/Supplement_04Nov2014.pdf
-
"Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Data Models with Weakly Exogenous Regressors", by Alexander Chudik, and M. Hashem Pesaran,CESifo Working Paper No. 4232 and CAFE Research Paper No. 13.14, IZA Discussion Paper No. 6618, forthcoming in the Journal of Econometrics July 2014.
Abstract: This paper extends the Common Correlated Effects (CCE) approach developed by Pesaran (2006) to heterogeneous panel data models with lagged dependent variable and/or weakly exogenous regressors. We show that the CCE mean group estimator continues to be valid but the following two conditions must be satisfied to deal with the dynamics: a sufficient number of lags of cross section averages must be included in individual equations of the panel, and the number of cross section averages must be at least as large as the number of unobserved common factors. We establish consistency rates, derive the asymptotic distribution, suggest using covariates to deal with the effects of multiple unobserved common factors, and consider jackknife and recursive de-meaning bias correction procedures to mitigate the small sample time series bias. Theoretical findings are accompanied by extensive Monte Carlo experiments, which show that the proposed estimators perform well so long as the time series dimension of the panel is sufficiently large.
JEL Classifications: C31, C33
Key Words: Large panels, lagged dependent variable, cross sectional dependence, coefficient heterogeneity, estimation and inference, common correlated effects, unobserved common factors.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp14/CP_DynamicCCE_3July2014.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/fp14/Supplement_28Jan2014.pdf
-
"Testing Weak Cross-Sectional Dependence in Large Panels", by M. Hashem Pesaran, January 2012, CWPE Working Paper No. 1208, IZA Discussion Paper No. 6432, forthcoming in Econometric Reviews
Abstract: This paper considers testing the hypothesis that errors in a panel data model are weakly cross sectionally dependent, using the exponent of cross-sectional dependence
, introduced recently in Bailey, Kapetanios and Pesaran (2012). It is shown that the implicit null of the CD test depends on the relative expansion rates of N and T. When T = O 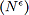 , for some
, for some 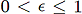 , then the implicit null of the CD test is given by
, then the implicit null of the CD test is given by 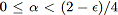 , which gives
, which gives 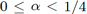 , when N and T tend to infinity at the same rate such that T/N
, when N and T tend to infinity at the same rate such that T/N 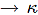 , with
, with 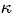 being a finite positive constant. It is argued that in the case of large N panels, the null of weak dependence is more appropriate than the null of independence which could be quite restrictive for large panels. Using Monte Carlo experiments, it is shown that the CD test has the correct size for values of in the range [0, 1/4], for all combinations of N and T, and irrespective of whether the panel contains lagged values of the dependent variables, so long as there are no major asymmetries in the error distribution.
being a finite positive constant. It is argued that in the case of large N panels, the null of weak dependence is more appropriate than the null of independence which could be quite restrictive for large panels. Using Monte Carlo experiments, it is shown that the CD test has the correct size for values of in the range [0, 1/4], for all combinations of N and T, and irrespective of whether the panel contains lagged values of the dependent variables, so long as there are no major asymmetries in the error distribution.
JEL Classifications: C12, C13, C3
Key Words: Exponent of cross-sectional dependence, Diagnostic tests, Panel data models, Dynamic heterogenous panels.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/Pesaran-WCD-Test-11-Jan-2013.pdf
-
"Debt, Inflation and Growth: Robust Estimation of Long-Run Effects in Dynamic Panel Data Models", by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, and Mehdi Raissi, November 2013
Abstract: This paper investigates the long-run effects of public debt and inflation on economic growth. Our contribution is both theoretical and empirical. On the theoretical side, we develop a cross-sectionally augmented distributed lag (CS-DL) approach to the estimation of long-run effects in dynamic heterogeneous panel data models with cross-sectionally dependent errors. The relative merits of the CS-DL approach and other existing approaches in the literature are discussed and illustrated with small sample evidence obtained by means of Monte Carlo simulations. On the empirical side, using data on a sample of 40 countries over the 1965-2010 period, we find significant negative long-run effects of public debt and inflation on growth. Our results indicate that, if the debt to GDP ratio is raised and this increase turns out to be permanent, then it will have negative effects on economic growth in the long run. But if the increase is temporary, then there are no long-run growth effects so long as debt to GDP is brought back to its normal level. We do not find a universally applicable threshold effect in the relationship between public debt and growth. We only find statistically significant threshold effects in the case of countries with rising debt to GDP ratios.
JEL Classifications: C23, E62, F34, H6
Key Words: Long-run relationships, estimation and inference, large dynamic heterogeneous panels, cross-section dependence, debt, inflation and growth, debt overhang
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/CMPR_18-November-2013.pdf
Video: http://youtu.be/5Zms8SAjsbc
Matlab Codes for the CS-DL Estimators: http://www.econ.cam.ac.uk/people-files/cto/km418/CMPR_CSDL.zip
Data and Stata Do File: http://www.econ.cam.ac.uk/people-files/cto/km418/CMPR_Data.zip
-
"A multi-country approach to forecasting output growth using PMIs", by Alexander Chudik, Valerie Grossmanz and M. Hashem Pesaran, November 2014
Abstract: This paper derives new theoretical results for forecasting with Global VAR (GVAR) models. It is shown that the presence of a strong unobserved common factor can lead to an undetermined GVAR model. To solve this problem, we propose augmenting the GVAR with additional proxy equations for the strong factors and establish conditions under which forecasts from the augmented GVAR model (AugGVAR) uniformly converge in probability (as the panel dimensions N,T [code] ∞ such that N/T → k for some 0 < k < ∞) to the infeasible optimal forecasts obtained from a factor-augmented high-dimensional VAR model. The small sample properties of the proposed solution are investigated by Monte Carlo experiments as well as empirically. In the empirical part, we investigate the value of the information content of Purchasing Managers Indices (PMIs) for forecasting global (48 countries) growth, and compare forecasts from Aug- GVAR models with a number of data-rich forecasting methods, including Lasso, Ridge, partial least squares and factor-based methods. It is found that (a) regardless of the forecasting meth- ods considered, PMIs are useful for nowcasting, but their value added diminishes quite rapidly with the forecast horizon, and (b) AugGVAR forecasts do as well as other data-rich forecasting techniques for short horizons, and tend to do better for longer forecast horizons.
JEL Classifications: C53, E37.
Key Words: Global VARs, High-dimensional VARs, Augmented GVAR, Forecasting, Nowcasting, Data-rich methods, GDP and PMIs
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/CGP_GDPnowcasting_10-November-2014.pdf
-
"Is There a Debt-threshold Effect on Output Growth?", by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran, and Mehdi Raissi, July 2015
Abstract: This paper studies the long-run impact of public debt expansion on economic growth and investigates whether the debt-growth relation varies with the level of indebtedness. Our contribution is both theoretical and empirical. On the theoretical side, we develop tests for threshold effects in the context of dynamic heterogeneous panel data models with cross-sectionally dependent errors and illustrate, by means of Monte Carlo experiments, that they perform well in small samples. On the empirical side, using data on a sample of 40 countries (grouped into advanced and developing) over the 1965-2010 period, we find no evidence for a universally applicable threshold effect in the relationship between public debt and economic growth, once we account for the impact of global factors and their spillover effects. Regardless of the threshold, however, we find significant negative long-run effects of public debt build-up on output growth. Provided that public debt is on a downward trajectory, a country with a high level of debt can grow just as fast as its peers.
JEL Classifications: C23, E62, F34, H6
Key Words: Panel tests of threshold effects, long-run relationships, estimation and inference, large dynamic heterogeneous panels, cross-section dependence, debt, and inflation.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/CMPR_July3_2015.pdf
Supplement: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/Supplement_03July2015.pdf
-
"A Multiple Testing Approach to the Regularisation of Large Sample Correlation Matrices", by Natalia Bailey, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.05, May 2014, revised January 2015
Abstract: This paper proposes a novel regularisation method for the estimation of large covariance matrices, using insights from the multiple testing (MT) literature. The method tests the statistical significance of individual pair-wise correlations and sets to zero those elements that are not statistically significant, taking account of the multiple testing nature of the problem. The procedure is straightforward to implement and is readily adapted to deal with non-Gaussian observations. By using the inverse of the normal distribution at a predetermined significance level, it circumvents the challenge of evaluating the theoretical constant arising in the rate of convergence of existing thresholding estimators, and hence does not require cross-validation. We compare the small sample performance of the proposed MT estimator to a number of other regularisation techniques in the literature using Monte Carlo experiments. We find that the MT estimator performs well and tends to outperform the other estimators, particularly when the cross-sectional dimension, N, is larger than the time series dimension, T. If the inverse covariance matrix is also of interest, then we propose a shrinkage version of the MT estimator that ensures positive definiteness.
JEL Classifications: C13, C58.
Key Words: Sparse correlation matrices, High-dimensional data, Multiple testing, Thresholding, Shrinkage.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/BPS_22-Jan-2015.pdf
Supplementary Material: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/BPS_Supplement_22-Jan2015.pdf
-
"Long-Run Effects in Large Heterogenous Panel Data Models with Cross-Sectionally Correlated Errors", by Alexander Chudik, Kamiar Mohaddes, M. Hashem Pesaran and Mehdi Raissi, January 2015
Abstract: This paper develops a cross-sectionally augmented distributed lag (CS-DL) approach to the estimation of long-run effects in large dynamic heterogeneous panel data models with cross- sectionally dependent errors. The asymptotic distribution of the CS-DL estimator is derived under coefficient heterogeneity in the case where the time dimension (T) and the cross-section dimension (N) are both large. The CS-DL approach is compared with more standard panel data estimators that are based on autoregressive distributed lag (ARDL) specifications. It is shown that unlike the ARDL type estimator, the CS-DL estimator is robust to misspecification of dynamics and error serial correlation. The theoretical results are illustrated with small sample evidence obtained by means of Monte Carlo simulations, which suggest that the performance of the CS-DL approach is often superior to the alternative panel ARDL estimates particularly when T is not too large and lies in the range of [code].
JEL Classifications: C23.
Key Words: Long-run relationships, estimation and inference, large dynamic heterogeneous panels, cross-section dependence.
Full Text: http://www.econ.cam.ac.uk/people-files/emeritus/mhp1/wp15/CS-DL_16-January-2015.pdf
-
"Robust Standard Errors in Transformed Likelihood Estimation of Dynamic Panel Data Models with Cross-Sectional Heteroskedasticity", by Kazuhiko Hayakawa and M. Hashem Pesaran, CWPE Working Paper No. 1224, IZA Discussion Paper 6583, Cesifo Working Paper No.3850, April 2012, revised January 2014
Abstract: This paper extends the transformed maximum likelihood approach for estimation of dynamic panel data models by Hsiao, Pesaran, and Tahmiscioglu (2002) to the case where the errors are cross-sectionally heteroskedastic. This extension is not trivial due to the incidental parameters problem and its implications for estimation and inference. We approach the problem by working with a mis-specified homoskedastic model, and then show that the transformed maximum likelihood estimator continues to be consistent even in the presence of cross-sectional heteroskedasticity. We also obtain standard errors that are robust to cross-sectional heteroskedasticity of unknown form. By means of Monte Carlo simulations, we investigate the finite sample behavior of the transformed maximum likelihood estimator and compare it with various GMM estimators proposed in the literature. Simulation results reveal that, in terms of median absolute errors and accuracy of inference, the transformed likelihood estimator outperforms the GMM estimators in almost all cases.
JEL Classifications: C12, C13, C23
Key Words: Dynamic Panels, Cross-sectional heteroskedasticity, Monte Carlo simulation, Transformed MLE, GMM estimation.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/Hayakawa_Pesaran_robustML_R1_27Jan -2014.pdf
Matlab Code: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/Matlab-code-and-data-for-TransML-Hayakawa-and-Pesaran-2012.zip
-
"Exponent of Cross-sectional Dependence: Estimation and Inference", by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, November 2013, revised December 2014
Abstract: In this paper we provide a characterization of the degree of cross-sectional dependence in a two dimensional array, [code] in terms of the rate at which the variance of the cross-sectional average of the observed data varies with N. We show that under certain conditions this is equivalent to the rate at which the largest eigenvalue of the covariance matrix of [code] rises with N. We represent the degree of cross-sectional dependence by
, defined by the standard deviation, Std [code], where [code] is a simple cross-sectional average of [code]. We refer to as the `exponent of crosssectional dependence', and show how it can be consistently estimated for values of > 1/2. We propose bias corrected estimators, derive their asymptotic properties and consider a number of extensions. We include a detailed Monte Carlo simulation study supporting the theoretical results. We also provide a number of empirical applications investigating the degree of inter-linkages of real and nancial variables in the global economy, the extent to which macroeconomic variables are interconnected across and within countries, and present recursive estimates of applied to excess returns on securities included in the Standard and Poor 500 index.
JEL Classifications: C21, C32
Key Words: Cross correlations, Cross-sectional dependence, Cross-sectional averages, Weak and strong factor models
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/BKP_Cross_Section_Exponent_3-(main)_Dec_2014.pdf
Supplementary Appendices: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/BKP_Cross_Section_Exponent_3-(suppl)_Dec_2014.pdf
-
"A Multiple Testing Approach to the Regularisation of Large Sample Correlation Matrices", by Natalia Bailey, M. Hashem Pesaran and L. Vanessa Smith, CAFE Research Paper No. 14.05, May 2014
Abstract: This paper proposes a novel regularisation method for the estimation of large covariance matrices, which makes use of insights from the multiple testing literature. The method tests the statistical significance of individual pair-wise correlations and sets to zero those elements that are not statistically significant, taking account of the multiple testing nature of the problem. The procedure is straightforward to implement, and does not require cross validation. By using the inverse of the normal distribution at a predetermined significance level, it circumvents the challenge of evaluating the theoretical constant arising in the rate of convergence of existing thresholding estimators. We compare the performance of our multiple testing (MT) estimator to a number of thresholding and shrinkage estimators in the literature in a detailed Monte Carlo simulation study. Results show that our MT estimator performs well in a number of different settings and tends to outperform other estimators, particularly when the cross-sectional dimension, N, is larger than the time series dimension, T: If the inverse covariance matrix is of interest then we recommend a shrinkage version of the MT estimator that ensures positive definiteness.
JEL Classifications: C13, C58.
Key Words: Sparse correlation matrices, High-dimensional data, Multiple testing, Thresholding, Shrinkage.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/BPS_19May14.pdf
-
"Constructing Multi-Country Rational Expectations Models", by Stephane Dees, M. Hashem Pesaran, Ron P. Smith and L. Vanessa Smith, CESifo Working Papers No. 3081, October 2012, forthcoming in Oxford Bulletin of Economics and Statistics.
Abstract: This paper considers some of the technical issues involved in using the GVAR approach to construct a multi-country rational expectations, RE, model and illustrates them with a new Keynesian model for 33 countries estimated with quarterly data over the period 1980-2011. The issues considered are: the measurement of steady states; the determination of exchange rates and the specification of the short-run country-specific models; the identification and estimation of the model subject to the theoretical constraints required for a determinate rational expectations solution; the solution of a large RE model; the structure and estimation of the covariance matrix; and the simulation of shocks. The model used as an illustration shows that global demand and supply shocks are the most important drivers of output, inflation and interest rates in the long run. By contrast, monetary or exchange rate shocks have only a short-run impact in the evolution of the world economy. The paper also shows the importance of international connections, directly as well as indirectly through spillover effects. Overall, ignoring global inter-connections as country-specific models do, could give rise to misleading conclusions.
JEL Classifications: C32, E17, F37, F42
Key Words: Global VAR (GVAR), Multi-country New Keynesian (MCNK) models, supply shocks, demand shocks, monetary policy shocks
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/DPSS_26June13.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/DPPS_MCNK_Supplement_26June2013.pdf
Readme Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Readme-Data-DPSS(2010).pdf
Transformed Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Transformed-Data-(1979Q1-2006Q4).zip
Source Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Source-Data-(1979Q1-2006Q4).zip
-
"Large Panel Data Models with Cross-Sectional Dependence: A Survey", by Alexander Chudik, and M. Hashem Pesaran, CESifo WP Number 4371, August 2013, forthcoming in B. H. Baltagi (Ed.), The Oxford Handbook on Panel Data. Oxford University Press.
Abstract: This paper provides an overview of the recent literature on estimation and inference in large panel data models with cross-sectional dependence. It reviews panel data models with strictly exogenous regressors as well as dynamic models with weakly exogenous regressors. The paper begins with a review of the concepts of weak and strong cross-sectional dependence, and discusses the exponent of cross-sectional dependence that characterizes the different degrees of cross-sectional dependence. It considers a number of alternative estimators for static and dynamic panel data models, distinguishing between factor and spatial models of cross-sectional dependence. The paper also provides an overview of tests of independence and weak cross-sectional dependence.
JEL Classifications: C31, C33
Key Words: Large panels, weak and strong cross-sectional dependence, factor structure, spatial dependence, tests of cross-sectional dependence.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/Chudik-Pesaran-Surevy-CSD-13-August-2013.pdf
-
"Tests of Policy Ineffectiveness in Macroeconometrics", by M. Hashem Pesaran and Ron P. Smith, CAFE Research Paper No. 14.07, June 2014
Abstract: This paper proposes tests of policy ineffectiveness in the context of macroeconometric rational expectations models. It is assumed that there is a policy intervention that takes the form of changes in the parameters of a policy rule, and that there are sufficient observations before and after the intervention. The test is based on the difference between the realisations of the outcome variable of interest and counterfactuals based on no policy intervention, using only the pre-intervention parameter estimates, and in consequence the Lucas Critique does not apply. The paper develops tests of policy ineffectiveness for a full structural model, with and without exogenous, policy or non-policy, variables. Asymptotic distributions of the proposed tests are derived both when the post intervention sample is fixed as the pre-intervention sample expands, and when both samples rise jointly but at different rates. The performance of the test is illustrated by a simulated policy analysis of a three equation New Keynesian Model, which shows that the test size is correct but the power may be low unless the model includes exogenous variables, or if the policy intervention changes the steady states, such as the inflation target.
JEL Classifications: C18, C54, E65.
Key Words: Counterfactuals, policy analysis, policy ineffectiveness test, macroeconomics.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/PS-on-PI_15-June-2014.pdf
-
"A Two Stage Approach to Spatiotemporal Analysis with Strong and Weak Cross-Sectional Dependence", by Natalia Bailey, Sean Holly, and M. Hashem Pesaran, December 2013, revised July 2014
Abstract: An understanding of the spatial dimension of economic and social activity requires methods that can separate out the relationship between spatial units that is due to the effect of common factors from that which is purely spatial even in an abstract sense. The same applies to the empirical analysis of networks in general. We use cross unit averages to extract common factors (viewed as a source of strong cross-sectional dependence) and compare the results with the principal components approach widely used in the literature. We then apply multiple testing procedures to the de-factored observations in order to determine significant bilateral correlations (signifying connections) between spatial units and compare this to an approach that just uses distance to determine units that are neighbours. We apply these methods to real house price changes at the level of Metropolitan Statistical Areas in the USA, and estimate a heterogeneous spatio-temporal model for the de-factored real house price changes and obtain significant evidence of spatial connections, both positive and negative.
JEL Classifications: C21, C23
Key Words: Spatial and factor dependence, spatio-temporal models, positive and negative connections, house price changes.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/bhp_Jul_19_2014.pdf
-
"Exponent of Cross-sectional Dependence: Estimation and Inference", by Natalia Bailey, George Kapetanios and M. Hashem Pesaran, November 2013
Abstract: In this paper we provide a characterization of the degree of cross-sectional dependence in a two dimensional array, [code] in terms of the rate at which the variance of the cross-sectional average of the observed data varies with N. We show that under certain conditions this is equivalent to the rate at which the largest eigenvalue of the covariance matrix of [code] rises with N. We represent the degree of cross-sectional dependence by
, defined by the standard deviation, [code], where [code] is a simple cross-sectional average of [code]. We refer to as the ‘exponent of cross-sectional dependence’, and show how it can be consistently estimated for values of > 1/2. We propose bias corrected estimators, derive their asymptotic properties and consider a number of extensions. We include a detailed Monte Carlo study supporting the theoretical results. We also provide a number of empirical applications investigating the degree of inter-linkages of real and financial variables in the global economy, the extent to which macroeconomic variables are interconnected across and within countries.
JEL Classifications: C21, C32
Key Words: Cross correlations, Cross-sectional dependence, Cross-sectional averages, Weak and strong factor models
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/BKP_Cross-Section-Exponent-5-November-2013.pdf
-
"Theory and Practice of GVAR Modeling", by Alexander Chudik, and M. Hashem Pesaran, SSRN Research Paper Series No. 14.04, May 2014
Abstract: The Global Vector Autoregressive (GVAR) approach has proven to be a very useful approach to analyze interactions in the global macroeconomy and other data networks where both the cross-section and the time dimensions are large. This paper surveys the latest developments in the GVAR modeling, examining both the theoretical foundations of the approach and its numerous empirical applications. We provide a synthesis of existing literature and highlight areas for future research.
JEL Classifications: C32, E17.
Key Words: Global VAR, global macroeconometric modelling, global interdependencies, policy simulations.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp14/cp_GVARs_8May2014.pdf
-
"An Exponential Class of Dynamic Binary Choice Panel Data Models with Fixed Effects", by Majid M. Al-Sadoon, Tong Li and M. Hashem Pesaran, CESifo Working Paper No. 4033, October 2012, revised December 2012
Abstract: This paper develops a model for dynamic binary choice panel data that allows for unobserved heterogeneity to be arbitrarily correlated with covariates. The model is of the exponential type. We derive moment conditions that enable us to eliminate the unobserved heterogeneity term and at the same time to identify the parameters of the model. We then propose GMM estimators that are consistent and asymptotically normally distributed at the root-n rate. We also study the conditional likelihood approach, which can only identify the effect of state dependence in our case. Monte Carlo experiments demonstrate the finite sample performance of our GMM estimators.
JEL Classifications: C23, C25
Key Words: Dynamic Discrete Choice, Fixed Effects, Panel Data, Initial Values, GMM, CMLE.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/DBC-10-24-12.pdf
-
"A Two Stage Approach to Spatiotemporal Analysis with Strong and Weak Cross-Sectional Dependence", by Natalia Bailey, Sean Holly, and M. Hashem Pesaran, December 2013
Abstract: An understanding of the spatial dimension of economic and social activity requires methods that can separate out the relationship between spatial units that is due to the effect of common factors from that which is purely spatial even in an abstract sense. The same applies to the empirical analysis of networks in general. We use cross unit averages to extract common factors (viewed as a source of strong cross-sectional dependence) and compare the results with the principal components approach widely used in the literature. We then apply multiple testing procedures to the de-factored observations in order to determine significant bilateral correlations (signifying connections) between spatial units and compare this to an approach that just uses distance to determine units that are neighbours. We apply these methods to real house price changes at the level of Metropolitan Statistical Areas in the USA, and estimate a heterogeneous spatio-temporal model for the de-factored real house price changes and obtain significant evidence of spatial connections, both positive and negative.
JEL Classifications: C21, C23
Key Words: Spatial and factor dependence, spatio-temporal models, positive and negative connections, house price changes.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/bhp_Dec_19_2013.pdf
-
"Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Data Models with Weakly Exogenous Regressors", by Alexander Chudik, and M. Hashem Pesaran, CESifo WP Number 4232, May 2013
Abstract: This paper extends the Common Correlated Effects (CCE) approach developed by Pesaran (2006) to heterogeneous panel data models with lagged dependent variable and/or weakly ex-ogenous regressors. We show that the CCE mean group estimator continues to be valid but the following two conditions must be satisfied to deal with the dynamics: a sufficient number of lags of cross section averages must be included in individual equations of the panel, and the number of cross section averages must be at least as large as the number of unobserved common factors. We establish consistency rates, derive the asymptotic distribution, suggest using covariates to deal with the effects of multiple unobserved common factors, and consider jackknife and recursive de-meaning bias correction procedures to mitigate the small sample time series bias. Theoretical findings are accompanied by extensive Monte Carlo experiments, which show that the proposed estimators perform well so long as the time series dimension of the panel is sufficiently large.
JEL Classifications: C31, C33
Key Words: large panels, lagged dependent variable, cross sectional dependence, coefficient heterogeneity, estimation and inference, common correlated effects, unobserved common factors.
Full Text: http://www.cesifo-group.de/ifoHome/publications/working-papers/CESifoWP/CESifoWPdetails?wp_id=19088472
-
"Counterfactual Analysis in Macroeconometrics: An Empirical Investigation into the Effects of Quantitative Easin", by M. Hashem Pesaran and Ron P Smith, IZA Discussion Paper No. 6618, May 2012, revised June 2012
Abstract: This paper is concerned with ex ante and ex post counterfactual analyses in the case of macroeconometric applications where a single unit is observed before and after a given policy intervention. It distinguishes between cases where the policy change affects the model's parameters and where it does not. It is argued that for ex post policy evaluation it is important that outcomes are conditioned on ex post realized variables that are invariant to the policy change but nevertheless influence the outcomes. The effects of the control variables that are determined endogenously with the policy outcomes can be solved out for the policy evaluation exercise. An ex post policy ineffectiveness test statistic is proposed. The analysis is applied to the evaluation of the effects of the quantitative easing (QE) in the UK after March 2009. It is estimated that a 100 basis points reduction in the spread due to QE has an impact effect on output growth of about one percentage point, but the policy impact is very quickly reversed with no statistically significant effects remaining within 9-12 months of the policy intervention.
JEL Classifications: C18, C54, E65
Key Words: Counterfactuals, policy evaluation, macroeconomics, quantitative easing (QE), UK economic policy.
Full Text: http://www.iza.org/en/webcontent/publications/papers/viewAbstract?dp_id=6618
-
"Optimal Forecasts in the Presence of Structural Breaks", by M. Hashem Pesaran, Andreas Pick and Mikhail Pranovich, (2013), forthcoming in Journal of Econometrics
Abstract: This paper considers the problem of forecasting under continuous and discrete structural breaks and proposes weighting observations to obtain optimal forecasts in the MSFE sense. We derive optimal weights for one step ahead forecasts. Under continuous breaks, our approach largely recovers exponential smoothing weights. Under discrete breaks, we provide analytical expressions for optimal weights in models with a single regressor, and asymptotically valid weights for models with more than one regressor. It is shown that in these cases the optimal weight is the same across observations within a given regime and differs only across regimes. In practice, where information on structural breaks is uncertain, a forecasting procedure based on robust optimal weights is proposed. The relative performance of our proposed approach is investigated using Monte Carlo experiments and an empirical application to forecasting real GDP using the yield curve across nine industrial economies.
JEL Classifications: C22, C53
Key Words: Forecasting, structural breaks, optimal weights, robust optimal weights, exponential smoothing.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/PPP-9-Feb-2013.pdf
Suppliment: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/PP-Web-Supplement.pdf
-
"Signs of Impact Effects in Time Series Regression Models", by M. Hashem Pesaran and Ron P Smith, CESifo Working Paper, CAFE Research Paper No. 13.22, (2013), forthcoming in Economics Letters
Abstract: In this paper we consider the problem of interpreting the signs of the estimated coeficients in multivariate time series regressions where the regressors are correlated. Using a continuous time model, we argue that focussing on the signs of individual coeficients in such regressions could be misleading and argue in favour of allowing for the indirect effects that arise due to the historical correlations amongst the regressors. For estimation from discrete time data we show that the sign of the total impact, including the direct and indirect effects, of a regressor can be obtained using a simple regression that only includes the regressor of interest.
JEL Classifications: C1, C5
Key Words: Regression coeficients, Impact effects.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/PS-Impact-Signs-7-October2013.pdf
-
"One Hundred Years of Oil Income and the Iranian Economy: A Curse or a Blessing?", by Kamiar Mohaddes, and M. Hashem Pesaran, CESifo Working Paper Series No. 4118, February 2013, forthcoming in Parvin Alizadeh and Hassan Hakimian (eds.), Iran and the Global Economy: Petro Populism, Islam and Economic Sanctions. Routledge, London.
Abstract: This paper examines the impact of oil revenues on the Iranian economy over the past hundred years, spanning the period 1908–2010. It is shown that although oil has been produced in Iran over a very long period, its importance in the Iranian economy was relatively small up until the early 1960s. It is argued that oil income has been both a blessing and a curse. Oil revenues when managed appropriately are a blessing, but their volatility (which in Iran is much higher than oil price volatility) can have adverse effects on real output, through excessively high and persistent levels of inflation. Lack of appropriate institutions and policy mechanisms which act as shock absorbers in the face of high levels of oil revenue volatility have also become a drag on real output. In order to promote growth, policies should be devised to control inflation; to serve as shock absorbers negating the adverse effects of oil revenue volatility; to reduce rent seeking activities; and to prevent excessive dependence of government finances on oil income.
JEL Classifications: E02, N15, Q32
Key Words: Oil price volatility, oil income, rent seeking, inflation, macroeconomic policy.
Available at SSRN: http://ssrn.com/abstract=2221860
-
"Panel Unit Root Test in the Presence of a Multifactor Error Structure", M. Hashem Pesaran, L. V. Smith, and T. Yamagata, December 2007. CWPE No. 0775, CESifo Working Papers, No. 2193, January 2008, IZA Discussion Paper No. 3254, December 2007. The University of York, Discussion Papers in Economics 08/03. Revised November 2012, forthcoming in Journal of Econometrics.
Abstract: This paper extends the cross-sectionally augmented panel unit root test (CIPS) proposed by Pesaran (2007) to the case of a multifactor error structure, and proposes a new panel unit root test based on a simple average of cross-sectionally augmented Sargan-Bhargava statistics (CSB). The basic idea is to exploit information regarding the m unobserved factors that are shared by k observed time series in addition to the series under consideration. Initially, we develop the tests assuming that m0, the true number of factors is known, and show that the limit distribution of the tests does not depend on any nuisance parameters, so long as
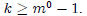 Small sample properties of the tests are investigated by Monte Carlo experiments and are shown to be satisfactory. Particularly, the proposed CIPS and CSB tests have the correct size for all combinations of the cross section (N) and time series (T) dimensions considered. The power of both tests rise with N and T, although the CSB test performs better than the CIPS test for smaller sample sizes. The various testing procedures are illustrated with empirical applications to real interest rates and real equity prices across countries.
Small sample properties of the tests are investigated by Monte Carlo experiments and are shown to be satisfactory. Particularly, the proposed CIPS and CSB tests have the correct size for all combinations of the cross section (N) and time series (T) dimensions considered. The power of both tests rise with N and T, although the CSB test performs better than the CIPS test for smaller sample sizes. The various testing procedures are illustrated with empirical applications to real interest rates and real equity prices across countries.
Key Words: Panel unit root tests, Cross section dependence, Multifactor error structure, Fisher inflation parity, Real equity prices.
JEL Classifications: C12, C15, C22, C23
Full Text: http://authors.elsevier.com/sd/article/S0304407613000353
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/20121022PSY_Supplement-(MS-No-2009229).pdf
Gauss Codes: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/Gauss_Code.zip
-
"Testing CAPM with a Large Number of Assets", by M. Hashem Pesaran and Takashi Yamagata, CWPE Working Paper No. 1210, IZA Discussion Paper No. 6469, under revision, February 2012, under revision
Abstract: This paper is concerned with testing the time series implications of the capital asset pricing model (CAPM) due to Sharpe (1964) and Lintner (1965), when the number of securities, N, is large relative to the time dimension, T, of the return series. In the case of cross-sectionally correlated errors, using a threshold estimator of the average squares of pair-wise error correlations a test is proposed and is shown to be valid even if N is much larger than T. Monte Carlo evidence show that the proposed test works well in small samples. The test is then applied to all securities in the S&P 500 index with 60 months of return data at the end of each month over the period September 1989-September 2011. Statistically significant evidence against Sharpe-Lintner CAPM is found mainly during the recent financial crisis. Furthermore, a strong negative correlation is found between a twelve-month moving average p-values of the test and the returns of long/short equity strategies relative to the return on S&P 500 over the period December 2006 to September 2011, suggesting that abnormal profits are earned during episodes of market inefficiencies.
JEL Classifications: C12, C15, C23, G11, G12
Key Words: CAPM, Testing for alpha, Market efficiency, Long/short equity returns, Large panels, Weak and strong cross-sectional dependence.
Full Text: http://www.iza.org/en/webcontent/publications/papers/viewAbstract?dp_id=6469
-
"An Empirical Growth Model for Major Oil Exporters", by Hadi Salehi Esfahani, Kamiar Mohaddes and M. Hashem Pesaran, (2012), forthcoming in Journal of Applied Econometrics
Abstract: This paper develops a long-run output relation for a major oil exporting economy where the oil income to output ratio remains sufficiently high over a prolonged period. It extends the stochastic growth model developed in Binder and Pesaran (1999) by including oil exports as an additional factor in the capital accumulation process. The paper distinguishes between the two cases where the growth of oil income, g0, is less than the natural growth rate (the sum of the population growth, n, and the growth of technical progress, g), and when g0 > g+n. Under the former, the effects of oil income on the economy's steady growth rate will vanish eventually, whilst under the latter, oil income enters the long-run output equation with a coefficient which is equal to the share of capital if it is further assumed that the underlying production technology can be represented by a Cobb-Douglas production function. The long-run theory is tested using quarterly data on nine major oil economies. Overall, the test results support the long-run theory, with the existence of long-run relations between real output, foreign output and real oil income established for six of the nine economies considered.
JEL Classifications: C32, C53, E17, F43, F47, Q32
Key Words: Growth models, long-run and error-correcting relations, major oil exporters, OPEC member countries, oil exports and foreign output shocks.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp12/EMP-JAE-4-June-2012.pdf
Data: /people-files/cto/km418/EMP_Data.zip
-
"Aggregation in Large Dynamic Panels", by M. Hashem Pesaran, Alexander Chudik, (2012), forthcoming in Journal of Econometrics
Abstract: This paper investigates the problem of aggregation in the case of large linear dynamic panels, where each micro unit is potentially related to all other micro units, and where micro innovations are allowed to be cross sectionally dependent. Following Pesaran (2003), an optimal aggregate function is derived and used (i) to establish conditions under which Granger's (1980) conjecture regarding the long memory properties of aggregate variables from 'a very large scale dynamic, econometric model' holds, and (ii) to show which distributional features of micro parameters can be identified from the aggregate model. The paper also derives impulse response functions for the aggregate variables, distinguishing between the effects of macro and aggregated idiosyncratic shocks. Some of the findings of the paper are illustrated by Monte Carlo experiments. The paper also contains an empirical application to consumer price inflation in Germany, France and Italy, and re-examines the extent to which 'observed' inflation persistence at the aggregate level is due to aggregation and/or common unobserved factors. Our findings suggest that dynamic heterogeneity as well as persistent common factors are needed for explaining the observed persistence of the aggregate inflation.
JEL Classifications: C43, E31
Key Words: Aggregation, Large Dynamic Panels, Long Memory, Weak and Strong Cross Section Dependence, VAR Models, Impulse Responses, Factor Models, Inflation Persistence.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp12/Pesaran-&-Chudik-Aggregation-1-March-2012.pdf
-
"Robust Standard Errors in Transformed Likelihood Estimation of Dynamic Panel Data Models", by Kazuhiko Hayakawa and M. Hashem Pesaran, CWPE Working Paper No. 1224, IZA Discussion Paper 6583, Cesifo Working Paper No.3850, April 2012, revised April 2012
Abstract: This paper extends the transformed maximum likelihood approach for estimation of dynamic panel data models by Hsiao, Pesaran, and Tahmiscioglu (2002) to the case where the errors are crosssectionally heteroskedastic. This extension is not trivial due to the incidental parameters problem that arises, and its implications for estimation and inference. We approach the problem by working with a mis-specified homoskedastic model. It is shown that the transformed maximum likelihood estimator continues to be consistent even in the presence of cross-sectional heteroskedasticity. We also obtain standard errors that are robust to cross-sectional heteroskedasticity of unknown form. By means of Monte Carlo simulation, we investigate the finite sample behavior of the transformed maximum likelihood estimator and compare it with various GMM estimators proposed in the literature. Simulation results reveal that, in terms of median absolute errors and accuracy of inference, the transformed likelihood estimator outperforms the GMM estimators in almost all cases.
JEL Classifications: C12, C13, C23
Key Words: Dynamic Panels, Cross-sectional heteroskedasticity, Monte Carlo simulation, GMM estimation.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/Hayakawa_Pesaran_robustML_27_April_2012.pdf
Matlab Code: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/Matlab-code-and-data-for-TransML-Hayakawa-and-Pesaran-2012.zip
-
"Signs of Impact Effects in Time Series Regression Models", by M. Hashem Pesaran and Ron P Smith, CESifo Working Paper, CAFE Research Paper No. 13.22 , October 2013
Abstract: In this paper we consider the problem of interpreting the signs of the estimated coeficients in multivariate time series regressions where the regressors are correlated. Using a continuous time model, we argue that focussing on the signs of individual coeficients in such regressions could be misleading and argue in favour of allowing for the indirect effects that arise due to the historical correlations amongst the regressors. For estimation from discrete time data we show that the sign of the total impact, including the direct and indirect effects, of a regressor can be obtained using a simple regression that only includes the regressor of interest.
JEL Classifications: C1, C5
Key Words: Regression coeficients, Impact effects.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/PS-Impact-Signs-7-October2013.pdf
-
"Large Panel Data Models with Cross-Sectional Dependence: A Survey", by Alexander Chudik, and M. Hashem Pesaran, CESifo WP Number 4371, August 2013
Abstract: This paper provides an overview of the recent literature on estimation and inference in large panel data models with cross-sectional dependence. It reviews panel data models with strictly exogenous regressors as well as dynamic models with weakly exogenous regressors. The paper begins with a review of the concepts of weak and strong cross-sectional dependence, and discusses the exponent of cross-sectional dependence that characterizes the different degrees of cross-sectional dependence. It considers a number of alternative estimators for static and dynamic panel data models, distinguishing between factor and spatial models of cross-sectional dependence. The paper also provides an overview of tests of independence and weak cross-sectional dependence.
JEL Classifications: C31, C33
Key Words: Large panels, weak and strong cross-sectional dependence, factor structure, spatial dependence, tests of cross-sectional dependence.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/Chudik-Pesaran-Surevy-CSD-13-August-2013.pdf
-
"One Hundred Years of Oil Income and the Iranian Economy: A Curse or a Blessing?", by Kamiar Mohaddes, and M. Hashem Pesaran, CESifo Working Paper Series No. 4118, December 2012, revised February 2013.
Abstract: This paper examines the impact of oil revenues on the Iranian economy over the past hundred years, spanning the period 1908–2010. It is shown that although oil has been produced in Iran over a very long period, its importance in the Iranian economy was relatively small up until the early 1960s. It is argued that oil income has been both a blessing and a curse. Oil revenues when managed appropriately are a blessing, but their volatility (which in Iran is much higher than oil price volatility) can have adverse effects on real output, through excessively high and persistent levels of inflation. Lack of appropriate institutions and policy mechanisms which act as shock absorbers in the face of high levels of oil revenue volatility have also become a drag on real output. In order to promote growth, policies should be devised to control inflation; to serve as shock absorbers negating the adverse effects of oil revenue volatility; to reduce rent seeking activities; and to prevent excessive dependence of government finances on oil income.
JEL Classifications: E02, N15, Q32
Key Words: Oil price volatility, oil income, rent seeking, inflation, macroeconomic policy.
Available at SSRN: http://ssrn.com/abstract=2221860
-
"Supply, Demand and Monetary Policy Shocks in a Multi-Country New Keynesian Model", by Stephane Dees, M. Hashem Pesaran, Ron P. Smith and L. Vanessa Smith, CESifo Working Papers No. 3081, June 2011, revised October 2012
Abstract: This paper estimates and solves a multi-country version of the standard New Keynesian, MCNK, model. Modelling a large number of countries requires a range of methodological innovations. Each country has a Phillips curve determining inflation, an IS curve determining output, a Taylor Rule determining interest rates, and a real effective exchange rate equation. All variables are measured as deviations from their steady states, estimated as long-horizon forecasts from a reduced-form cointegrating global VAR. The rational expectations model is estimated for 33 countries, 1980Q1-2006Q4, by inequality constrained IV, using lagged and contemporaneous foreign variables as instruments, subject to NK theoretical restrictions. The MCNK model is then solved to provide estimates of identified supply, demand and monetary policy shocks. Within a country supply, demand and monetary policy shocks are orthogonal, though shocks of the same type (e.g. supply shocks in different countries) can be correlated. We present impulse response functions and variance decompositions allowing for both direct channels of international transmission through regression coefficients and indirect channels through error spillover effects. Bootstrapped error bands are also provided for the cross country responses of a shock to the US monetary policy.
JEL Classifications: C32, E17, F37, F42
Key Words: Global VAR (GVAR), Multi-country New Keynesian (MCNK) models, supply shocks, demand shocks, monetary policy shocks
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/DPSS_MCNKJune2011.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/DPSS_MCNK_Supplement_June2011.pdf
Readme Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Readme-Data-DPSS(2010).pdf
Transformed Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Transformed-Data-(1979Q1-2006Q4).zip
Source Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Source-Data-(1979Q1-2006Q4).zip
-
"Counterfactual Analysis in Macroeconometrics: An Empirical Investigation into the Effects of Quantitative Easin", by M. Hashem Pesaran and Ron P Smith, May 2012
Abstract: This paper is concerned with ex ante and ex post counterfactual analyses in the case of macroeconometric applications where a single unit is observed before and after a given policy intervention. It distinguishes between cases where the policy change affects the model's parameters and where it does not. It is argued that for ex post policy evaluation it is important that outcomes are conditioned on ex post realized variables that are invariant to the policy change but nevertheless influence the outcomes. The effects of the control variables that are determined endogenously with the policy outcomes can be solved out for the policy evaluation exercise. An ex post policy ineffectiveness test statistic is proposed. The analysis is applied to the evaluation of the effects of the quantitative easing (QE) in the UK after March 2009. It is estimated that a 100 basis points reduction in the spread due to QE has an impact effect on output growth of about one percentage point, but the policy impact is very quickly reversed with no statistically significant effects remaining within 9-12 months of the policy intervention.
JEL Classifications: C18, C54, E65
Key Words: Counterfactuals, policy evaluation, macroeconomics, quantitative easing (QE), UK economic policy.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/PS-on-CF-16May2012.pdf
-
"One Hundred Years of Oil Income and the Iranian Economy: A Curse or a Blessing?", by Kamiar Mohaddes, and M. Hashem Pesaran, December 2012
Abstract: This paper examines the impact of oil revenues on the Iranian economy over the past hundred years, spanning the period 1908–2010. It is shown that although oil has been produced in Iran over a very long period, its importance in the Iranian economy was relatively small up until the early 1960s. It is argued that oil income has been both a blessing and a curse. Oil revenues when managed appropriately are a blessing, but their volatility (which in Iran is much higher than oil price volatility) can have adverse effects on real output, through excessively high and persistent levels of inflation. Lack of appropriate institutions and policy mechanisms which act as shock absorbers in the face of high levels of oil revenue volatility have also become a drag on real output. In order to promote growth, policies should be devised to control inflation; to serve as shock absorbers negating the adverse effects of oil revenue volatility; to reduce rent seeking activities; and to prevent excessive dependence of government finances on oil income.
JEL Classifications: E02, N15, Q32
Key Words: Oil price volatility, oil income, rent seeking, inflation, macroeconomic policy.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/DBC-10-24-12.pdf
-
"Testing Weak Cross-Sectional Dependence in Large Panels", by M. Hashem Pesaran, January 2012, Revised January 2013
Abstract: This paper considers testing the hypothesis that errors in a panel data model are weakly cross sectionally dependent, using the exponent of cross-sectional dependence
, introduced recently in Bailey, Kapetanios and Pesaran (2012). It is shown that the implicit null of the CD test depends on the relative expansion rates of N and T. When T = O , for some  , then the implicit null of the CD test is given by , which gives , when N and T tend to infinity at the same rate such that T/N , with being a finite positive constant. It is argued that in the case of large N panels, the null of weak dependence is more appropriate than the null of independence which could be quite restrictive for large panels. Using Monte Carlo experiments, it is shown that the CD test has the correct size for values of in the range [0, 1/4], for all combinations of N and T, and irrespective of whether the panel contains lagged values of the dependent variables, so long as there are no major asymmetries in the error distribution.
, then the implicit null of the CD test is given by , which gives , when N and T tend to infinity at the same rate such that T/N , with being a finite positive constant. It is argued that in the case of large N panels, the null of weak dependence is more appropriate than the null of independence which could be quite restrictive for large panels. Using Monte Carlo experiments, it is shown that the CD test has the correct size for values of in the range [0, 1/4], for all combinations of N and T, and irrespective of whether the panel contains lagged values of the dependent variables, so long as there are no major asymmetries in the error distribution.
JEL Classifications: C12, C13, C3
Key Words: Exponent of cross-sectional dependence, Diagnostic tests, Panel data models, Dynamic heterogenous panels.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/Pesaran-WCD-Test-11-Jan-2013.pdf
-
"Econometric Analysis of High Dimensional VARs Featuring a Dominant Unit", by M. Hashem Pesaran and Alexander Chudik, (2011), forthcoming in the Econometrics Review.
Abstract: This paper extends the analysis of infinite dimensional vector autoregressive (IVAR) models proposed in Chudik and Pesaran (2011) to the case where one of the variables or the cross section units in the IVAR model is dominant or pervasive. It is an important extension from empirical as well theoretical perspectives. In the theory of networks a dominant unit is the centre node of a star network and arises as an efficient outcome of a distance-based utility model. Empirically, the extension poses a number of technical challenges that goes well beyond the analysis of IVAR models provided in Chudik and Pesaran. This is because the dominant unit influences the rest of the variables in the IVAR model both directly and indirectly, and its effects do not vanish as the dimension of the model (N) tends to infinity. The dominant unit acts as a dynamic factor in the regressions of the non-dominant units and yields an infinite order distributed lag relationship between the two types of units. Despite this it is shown that the effects of the dominant unit as well as those of the neighborhood units can be consistently estimated by running augmented least squares regressions that include distributed lag functions of the dominant unit and its neighbors (if any). The asymptotic distribution of the estimators is derived and their small sample properties investigated by means of Monte Carlo experiments.
JEL Classifications: C10, C33, C51
Key Words: IVAR Models, Dominant Units, Star Networks, Large Panels, Weak and Strong Cross Section Dependence, Factor Models, Spatial Models.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp11/PesaranChudik_IVARD_1 April 11.pdf
-
"Common Correlated Effects Estimation of Heterogeneous Dynamic Panel Data Models with Weakly Exogenous Regressors", by Alexander Chudik, and M. Hashem Pesaran, April 2013
Abstract: This paper extends the Common Correlated Effects (CCE) approach developed by Pesaran (2006) to heterogeneous panel data models with lagged dependent variable and/or weakly exogenous regressors. We show that the CCE mean group estimator continues to be valid but the following two conditions must be satisfied to deal with the dynamics: a sufficient number of lags of cross section averages must be included in individual equations of the panel, and the number of cross section averages must be at least as large as the number of unobserved common factors. We establish consistency rates, derive the asymptotic distribution, suggest using covariates to deal with the effects of multiple unobserved common factors, and consider jackknife and recursive de-meaning bias correction procedures to mitigate the small sample time series bias. Theoretical findings are accompanied by extensive Monte Carlo experiments, which show that the proposed estimators perform well so long as the time series dimension of the panel is sufficiently large.
JEL Classifications: C31, C33
Key Words: Large panels, lagged dependent variable, cross sectional dependence, coefficient heterogeneity, estimation and inference, common correlated effects, unobserved common factors.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp13/CP_DynamicCCE_25 Apr-2013.pdf
-
"Panel Unit Root Test in the Presence of a Multifactor Error Structure", M. Hashem Pesaran, L. V. Smith, and T. Yamagata, (2013), forthcoming in Journal of Econometrics, Revised 2012
Abstract: This paper extends the cross-sectionally augmented panel unit root test (CIPS) proposed by Pesaran (2007) to the case of a multifactor error structure, and proposes a new panel unit root test based on a simple average of cross-sectionally augmented Sargan-Bhargava statistics (CSB). The basic idea is to exploit information regarding the m unobserved factors that are shared by k observed time series in addition to the series under consideration. Initially, we develop the tests assuming that m0, the true number of factors is known, and show that the limit distribution of the tests does not depend on any nuisance parameters, so long as
Small sample properties of the tests are investigated by Monte Carlo experiments and are shown to be satisfactory. Particularly, the proposed CIPS and CSB tests have the correct size for all combinations of the cross section (N) and time series (T) dimensions considered. The power of both tests rise with N and T, although the CSB test performs better than the CIPS test for smaller sample sizes. The various testing procedures are illustrated with empirical applications to real interest rates and real equity prices across countries.
Key Words: Panel Unit Root Tests, Cross Section Dependence, Multifactor Error Structure, Fisher Inflation Parity, Real Equity Prices.
JEL Classifications: C12, C15, C22, C23
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/Panel-Unit-PSY-(MS-No-2009229_4).pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/20121022PSY_Supplement-(MS-No-2009229).pdf
Gauss Codes: http://www.econ.cam.ac.uk/emeritus/mhp1/fp13/Gauss_Code.zip
-
"A Panel Unit Root Test in the Presence of a Multifactor Error Structure", M. Hashem Pesaran, L. V. Smith, and T. Yamagata. December, 2007, Revised September 2009
Abstract: This paper extends the cross sectionally augmented panel unit root test proposed by Pesaran (2007) to the case of a multifactor error structure. The basic idea is to exploit information regarding the m unobserved factors that are shared by k other time series in addition to the variable under consideration. Initially we develop a test assuming that
 , the true number of factors is known, and show that the limit distribution of the test does not depend on any nuisance parameters, so long as
, the true number of factors is known, and show that the limit distribution of the test does not depend on any nuisance parameters, so long as  Small sample properties of the test are investigated by Monte Carlo experiments and shown to be satisfactory. Particularly, in contrast to other existing panel unit root tests, our test has correct size and reasonable power for the case with an intercept and a linear trend as well as with an intercept only, for all combinations of cross section and time series dimensions. An illustrative application is also provided where the proposed panel unit root test is applied to Fisher’s inflation parity and real equity prices.
Small sample properties of the test are investigated by Monte Carlo experiments and shown to be satisfactory. Particularly, in contrast to other existing panel unit root tests, our test has correct size and reasonable power for the case with an intercept and a linear trend as well as with an intercept only, for all combinations of cross section and time series dimensions. An illustrative application is also provided where the proposed panel unit root test is applied to Fisher’s inflation parity and real equity prices.
Key Words: Panel Unit Root Tests, Cross Section Dependence, Multi-factor Residual Structure, Fisher Inflation Parity, Real Equity Prices..
JEL Classifications: C12, C15, C22, C23
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp09/PSY_16Sept2009_Vanessa.pdf
Gauss Codes and Supplemental Critical Value Tables: http://www.econ.cam.ac.uk/emeritus/mhp1/wp08/CIPSM.zip
-
"Business Cycle Effects of Credit and Technology Shocks in a DSGE Model with Firm Default", by M. Hashem Pesaran and TengTeng Xu, October 2011
Abstract: This paper proposes a theoretical framework to analyze the impacts of credit and technology shocks on business cycle dynamics, where firms rely on banks and households for capital financing. Firms are identical ex ante but differ ex post due to different realizations of firm specific technology shocks, possibly leading to default by some firms. The paper advances a new modelling approach for the analysis of financial intermediation and firm defaults that takes account of the financial implications of such defaults for both households and banks. Results from a calibrated version of the model highlights the role of financial institutions in the transmission of credit and technology shocks to the real economy. A positive credit shock, defined as a rise in the loan to deposit ratio, increases output, consumption, hours and productivity, and reduces the spread between loan and deposit rates. The effects of the credit shock tend to be highly persistent even without price rigidities and habit persistence in consumption behaviour.
JEL Classifications: E32, E44, G21.
Key Words: Bank Credit, Financial Intermediation, Firm Heterogeneity and Defaults, Interest Rate Spread, Real Financial Linkages.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/MacroCredit_ 6Oct2011_WorkingPaper.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/MacroCredit_ 5Oct2011_Supplement.pdf
-
"Optimal Forecasts in the Presence of Structural Breaks", by M. Hashem Pesaran, Andreas Pick and Mikhail Pranovich, October 2011, Revised December 2011
Abstract: This paper considers the problem of forecasting under continuous and discrete structural breaks and proposes weighting observations to obtain optimal forecasts in the MSFE sense. We derive optimal weights for continuous and discrete break processes. Under continuous breaks, our approach recovers exponential smoothing weights. Under discrete breaks, we provide analytical expressions for the weights in models with a single regressor and asympotically for larger models. It is shown that in these cases the value of the optimal weight is the same across observations within a given regime and differs only across regimes. In practice, where information on structural breaks is uncertain a forecasting procedure based on robust weights is proposed. Monte Carlo experiments and an empirical application to the predictive power of the yield curve analyze the performance of our approach relative to other forecasting methods.
JEL Classifications: C22, C53
Key Words: Forecasting, structural breaks, optimal weights, robust weights, exponential smoothing.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/PPP-9-Dec-2011.pdf
-
"On Identification of Bayesian DSGE Models", by Gary Koop, M. Hashem Pesaran and Ron P. Smith, March 2011, Revised August 2012
Abstract: This paper is concerned with identification of dynamic stochastic general equilibrium (DSGE) models from a Bayesian perspective, and proposes two Bayesian indicators. The first indicator follows a suggestion by Poirier of comparing the posterior density of the parameter of interest with the posterior expectation of its prior conditional on the remaining parameters, as opposed to comparing the posterior distribution to its prior as is usually done.
The second indicator examines the rate at which the posterior precision of the parameter gets updated with the sample size, using simulated data. For identified parameters the posterior precision increases at rate T. We show that for parameters that are either unidentified or are weakly identified the posterior precision may be updated but its rate of update will be slower than T. We use empirical examples to demonstrate that these methods are useful in practice.
JEL Classifications: C11, C15, E17
Key Words: Bayesian identification, weak identification, DSGE models, posterior updating.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/KPS6August12.pdf
-
"Testing Weak Cross-Sectional Dependence in Large Panels", by M. Hashem Pesaran, January 2012
Abstract: This paper considers testing the hypothesis that errors in a panel data model are weakly cross sectionally dependent, using the exponent of cross-sectional dependence
, introduced recently in Bailey, Kapetanios and Pesaran (2012). It is shown that the implicit null of the CD test depends on the relative expansion rates of N and T. When T = O , for some , then the implicit null of the CD test is given by , which gives  , when N and T tend to infinity at the same rate such that T/N , with being a finite positive constant. It is argued that in the case of large N panels, the null of weak dependence is more appropriate than the null of independence which could be quite restrictive for large panels. Using Monte Carlo experiments, it is shown that the CD test has the correct size for values of
, when N and T tend to infinity at the same rate such that T/N , with being a finite positive constant. It is argued that in the case of large N panels, the null of weak dependence is more appropriate than the null of independence which could be quite restrictive for large panels. Using Monte Carlo experiments, it is shown that the CD test has the correct size for values of  in the range [0, 1/4], for all combinations of N and T, and irrespective of whether the panel contains lagged values of the dependent variables, so long as there are no major asymmetries in the error distribution.
in the range [0, 1/4], for all combinations of N and T, and irrespective of whether the panel contains lagged values of the dependent variables, so long as there are no major asymmetries in the error distribution.
JEL Classifications: C12, C13, C3
Key Words: Exponent of cross-sectional dependence, Diagnostic tests, Panel data models, Dynamic heterogenous panels.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/Pesaran-WCD-Test-30-Jan-2012.pdf
-
"On Identification of Bayesian DSGE Models", by Gary Koop, M. Hashem Pesaran and Ron P. Smith, March 2011, Revised September 2011
Abstract: In recent years there has been increasing concern about the identi…fication of parameters in dynamic stochastic general equilibrium (DSGE) models. Given the structure of DSGE models it may be difficult to determine whether a parameter is identified. For the researcher using Bayesian methods, a lack of identification may not be evident since the posterior of a parameter of interest may differ from its prior even if the parameter is unidentified. We show that this can be the case even if the priors assumed on the structural parameters are independent. We suggest two Bayesian identification indicators that do not suffer from this difficulty and are relatively easy to compute. The first applies to DSGE models where the parameters can be partitioned into those that are known to be identified and the rest where it is not known whether they are identified. In such cases the marginal posterior of an unidentified parameter will equal the posterior expectation of the prior for that parameter conditional on the identified parameters. The second indicator is more generally applicable and considers the rate at which the posterior precision gets updated as the sample size (T) is increased. For identified parameters the posterior precision rises with T, whilst for an unidentified parameter its posterior precision may be updated but its rate of update will be slower than T. This result assumes that the identified parameters are
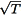 -consistent, but similar differential rates of updates for identified and unidentified parameters can be established in the case of weak (or super) consistent estimators. These results are illustrated by means of simple DSGE models.
-consistent, but similar differential rates of updates for identified and unidentified parameters can be established in the case of weak (or super) consistent estimators. These results are illustrated by means of simple DSGE models.
JEL Classifications: C11, C15, E17
Key Words: Bayesian identification, DSGE models, posterior updating, New Keynesian Phillips Curve.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/KPS30Sept11.pdf
-
"Oil Exports and the Iranian Economy", by Hadi Salehi Esfahani, Kamiar Mohaddes and M. Hashem Pesaran, April 2012
Abstract: This paper presents an error-correcting macroeconometric model for the Iranian economy estimated using a new quarterly data set over the period 1979Q1-2006Q4. It builds on a recent paper by the authors, Esfahani et al. (2012), which develops a theoretical long-run growth model for major oil exporting economies. The core variables included in this paper are real output, real money balances, inflation, exchange rate, oil exports, and foreign real output, although the role of investment and consumption are also analyzed in a sub-model. The paper finds clear evidence for the existence of two long-run relations: an output equation as predicted by the theory and a standard real money demand equation with inflation acting as a proxy for the (missing) market interest rate. The results show that real output in the long run is influenced by oil exports and foreign output. However, it is also found that inflaation has a signifiicant negative long-run effect on real GDP, which is suggestive of economic inefficiencies and is matched by a negative association between inflation and the investment-output ratio. Finally, the results of impulse responses show that the Iranian economy adjusts quite quickly to the shocks in foreign output and oil exports, which could be partly due to the relatively underdeveloped nature of Iran’s financial markets.
JEL Classifications: C32, C53, E17, F43, F47, Q32
Key Words: Growth models, long-run relations, oil exporters, Iranian economy, oil price and foreign output shocks, and error-correcting relations.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp12/Iran_VARX_18 April 12.pdf
-
"Oil Exports and the Iranian Economy", by Hadi Salehi Esfahani, Kamiar Mohaddes, and M. Hashem Pesaran October, 2009
Abstract: This paper develops a long run growth model for a major oil exporting economy and derives conditions under which oil revenues are likely to have a lasting impact. This approach contrasts with the standard literature on the "Dutch disease" and the "resource curse", which primarily focus on short run implications of a temporary resource discovery. Under certain regularity conditions and assuming a Cobb Douglas production function, it is shown that (log) oil exports enter the long run output equation with a coeficient equal to the share of capital. The long run theory is tested using a new quarterly data set on the Iranain economy over the period 1979Q1-2006Q4. Building an error correction specification in real output, real money balances, inflation, real exchange rate, oil exports, and foreign real output, the paper finds clear evidence for two long run relations: an output equation as predicted by the theory and a standard real money demand equation with inflation acting as a proxy for the (missing) market interest rate. Real output in the long run is shaped by oil exports through their impact on capital accumulation, and the foreign output as the main channel of technological transfer. The results also show a significant negative long run association between inflation and real GDP, which is suggestive of economic ineficiencies. Once the effects of oil exports are taken into account, the estimates support output growth convergence between Iran and the rest of the world. We also find that the Iranian economy adjusts quite quickly to the shocks in foreign output and oil exports, which could be partly due to the relatively underdeveloped nature of Iran’s financial markets.
JEL Classifications: Growth models, long run relations, Iranian economy, oil price and foreign output shocks, and error correcting relations.
Key Words: C32, C53, E17, F43, F47, Q32.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp09/Iran_VARX_08Oct09.pdf
Data: http://www.econ.cam.ac.uk/teach/mohaddes/Iran_VARX_Data.zip
-
"On the Interpretation of Panel Unit Root Tests", by M. Hashem Pesaran, September 2011
Abstract: Applications of panel unit root tests have become commonplace in empirical economics, yet there are ambiguities as how best to interpret the test results. This note clarifies that rejection of the panel unit root hypothesis should be interpreted as evidence that a statistically significant proportion of the units are stationary. Accordingly, in the event of a rejection, and in applications where the time dimension of the panel is relatively large, it recommends the test outcome to be augmented with an estimate of the proportion of the cross-section units for which the individual unit root tests are rejected. The economic importance of the rejection can be measured by the magnitude of this proportion.
JEL Classifications: C12, C33, C52
Key Words: Unit Root tests, Panels, Statistical Significance.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/Interpretation-Panel-Unit-September-2011.pdf
-
"Aggregation in Large Dynamic Panels", by M. Hashem Pesaran, Alexander Chudik, January 2011, Revised November 2011
Abstract: This paper investigates the problem of aggregation in the case of large linear dynamic panels, where each micro unit is potentially related to all other micro units, and where micro innovations are allowed to be cross sectionally dependent. Following Pesaran (2003), an optimal aggregate function is derived and used (i) to establish conditions under which Granger’s (1980) conjecture regarding the long memory properties of aggregate variables from ‘a very large scale dynamic, econometric model’holds, and (ii) to show which distributional features of micro parameters can be identified from the aggregate model. The paper also derives impulse response functions for the aggregate variables, distinquishing between the effects of macro and aggregated idiosyncratic shocks. Some of the findings of the paper are illustrated by Monte Carlo experiments. The paper also contains an empirical application to consumer price inflation in Germany, France and Italy, and re-examines the extent to which ‘observed’inflation persistence at the aggregate level is due to aggregation and/or common unobserved factors. Our findings suggest that dynamic heterogeneity as well as persistent common factors are needed for explaining the observed persistence of the aggregate inflation.
JEL Classifications: C43, E31
Key Words: Aggregation, Large Dynamic Panels, Long Memory,Weak and Strong Cross Section Dependence, VAR Models, Impulse Responses, Factor Models, Inflation Persistenc.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/PesaranChudik_Aggregation_16_Nov_2011.pdf
-
"Beyond the DSGE Straitjacket, by M. Hashem Pesaran and Ron P. Smith, May 2011
Abstract: Academic macroeconomics and the research department of central banks have come to be dominated by Dynamic, Stochastic, General Equilibrium (DSGE) models based on micro-foundations of optimising representative agents with rational expectations. We argue that the dominance of this particular sort of DSGE and the resistance of some in the profession to alternatives has become a straitjacket that restricts empirical and theoretical experimentation and inhibits innovation and that the profession should embrace a more flexible approach to macroeconometric modelling. We describe one possible approach.
JEL Classifications: C100, E100
Key Words: macroeconometric models, DSGE, VARs, long run theory.
Full Text: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1844075
-
"China's Emergence in the World Economy and Business Cycles in Latin America", by Ambrogio Cesa-Bianchi, M. Hashem Pesaran, Alessandro Rebucci and TengTeng Xu, July 2011
Abstract: The international business cycle is very important for Latin America's economic performance as the recent global crisis vividly illustrated. This paper investigates how changes in trade linkages between China, Latin America, and the rest of the world have altered the transmission mechanism of international business cycles to Latin America. Evidence based on a Global Vector Autoregressive (GVAR) model for 5 large Latin American economies and all major advanced and emerging economies of the world shows that the long-term impact of a China GDP shock on the typical Latin American economy has increased by three times since mid-1990s. At the same time, the long-term impact of a US GDP shock has halved, while the transmission of shocks to Latin America and the rest of emerging Asia (excluding China and India) GDP has not undergone any signi cant change. Contrary to common wisdom, we find that these changes owe more to the changed impact of China on Latin America's traditional and largest trading partners than to increased direct bilateral trade linkages boosted by the decade-long commodity price boom. These findings help to explain why Latin America did so well during the global crisis, but point to the risks associated with a deceleration in China's economic growth in the future for both Latin America and the rest of the world economy. The evidence reported also suggests that the emergence of China as an important source of world growth might be the driver of the so called "decoupling" of emerging markets business cycle from that of advanced economies reported in the existing literature.
JEL Classifications: C32, F44, E32, O54
Key Words: China, GVAR, Great Recession, Emerging Markets, International Business Cycle, Latin America, Trade linkages.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/CPRX_ECONOMIA_July27.pdf
-
"Beyond the DSGE straitjacket", by M. Hashem Pesaran and Ron P. Smith, April 2011
Abstract: Academic macroeconomics and the research department of central banks have come to be dominated by Dynamic, Stochastic, General Equilibrium (DSGE) models based on micro-foundations of optimising representative agents with rational expectations. We argue that the dominance of this particular sort of DSGE and the resistance of some in the profession to alternatives has become a straitjacket that restricts empirical and theoretical experimentation and inhibits innovation and that the profession should embrace a more flexible approach to macroeconometric modelling. We describe one possible approach.
JEL Classifications: C1, E1
Key Words: Macroeconometric models, DSGE, VARs, long run theory
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp11/Pesaran-and-Smith-2011-SSRN-id1844075.pdf
-
"Econometric Analysis of High Dimensional VARs Featuring a Dominant Unit", by M. Hashem Pesaran and Alexander Chudik. March, 2010
Abstract: This paper extends the analysis of infinite dimensional vector autoregressive models (IVAR) proposed in Chudik and Pesaran (2010) to the case where one of the variables or the cross section units in the IVAR model is dominant or pervasive. This extension is not straightforward and involves several technical difficulties. The dominant unit influences the rest of the variables in the IVAR model both directly and indirectly, and its effects do not vanish even as the dimension of the model (N) tends to infinity. The dominant unit acts as a dynamic factor in the regressions of the non-dominant units and yields an infinite order distributed lag relationship between the two types of units. Despite this it is shown that the effects of the dominant unit as well as those of the neighborhood units can be consistently estimated by running augmented least squares regressions that include distributed lag functions of the dominant unit. The asymptotic distribution of the estimators is derived and their small sample properties investigated by means of Monte Carlo experiments.
JEL Classifications: C10, C33, C51
Key Words: IVAR Models, Dominant Units, Large Panels, Weak and Strong Cross Section Dependence, Factor Models
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/PesaranChudik_IVARD_19Mar10.pdf
-
"Supply, Demand and Monetary Policy Shocks in a Multi-Country New Keynesian Model", by Stephane Dees, M. Hashem Pesaran, L. Vanessa Smith and Ron P. Smith. May, 2010
Abstract: This paper estimates and solves a multi-country version of the standard DSGE New Keynesian (NK) model. The country-specific models include a Phillips curve determining inflation, an IS curve determining output, a Taylor Rule determining interest rates, and a real effective exchange rate equation. The IS equation includes a real exchange rate variable and a countryspecific foreign output variable to capture direct inter-country linkages. In accord with the theory all variables are measured as deviations from their steady states, which are estimated as long-horizon forecasts from a reduced-form cointegrating global vector autoregression. The resulting rational expectations model is then estimated for 33 countries on data for 1980Q1- 2006Q4, by inequality constrained IV, using lagged and contemporaneous foreign variables as instruments, subject to the restrictions implied by the NK theory. The multi-country DSGE NK model is then solved to provide estimates of identified supply, demand and monetary policy shocks. Following the literature, we assume that the within country supply, demand and monetary policy shocks are orthogonal, though shocks of the same type (e.g. supply shocks in different countries) can be correlated. We discuss estimation of impulse response functions and variance decompositions in such large systems, and present estimates allowing for both direct channels of international transmission through regression coefficients and indirect channels through error spillover effects. Bootstrapped error bands are also provided for the cross country responses of a shock to the US monetary policy.
JEL Classifications: C32, E17, F37, F42
Key Words: Global VAR (GVAR), New Keynesian DSGE models, supply shocks, demand shocks, monetary policy shocks.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Dees-Pesaran-Smith-Smith-MCNK-28-May10.pdf
Supplement: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/DPSS_MCNK_Supplement_27July10.pdf
Readme Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Readme-Data-DPSS(2010).pdf
Transformed Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Transformed-Data-(1979Q1-2006Q4).zip
Source Data: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/Source-Data-(1979Q1-2006Q4).zip
-
"Diagnostic Tests of Cross Section Independence for Limited Dependent Variable Panel Data Models", by Cheng Hsiao, M. Hashem Pesaran and Andreas Pick April, 2007, Revised July 2010
Abstract: This paper considers the problem of testing for cross section independence in limited dependent variable panel data models. It derives a Lagrangian multiplier (LM) test and shows that in terms of generalized residuals of Gourieroux, Monfort, Renault and Trognon (1987) it reduces to the LM test of Breusch and Pagan (1980). Due to the tendency of the LM test to over-reject in panels with large N (cross section dimension), we also consider the application of the cross section dependence test (CD) proposed by Pesaran (2004). In Monte Carlo experiments it emerges that for most combinations of N and T the CD test is correctly sized, whereas the validity of the LM test requires T (time series dimension) to be quite large relative to N. We illustrate the cross-sectional independence tests by an application to a probit panel of roll-call votes in the U. S. Congress and find that the votes display a significant degree of cross section dependence.
JEL Classifications: C12, C33, C35
Key Words: Nonlinear panels, cross section dependence, probit and To-bit models
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/CDP_28July2010.pdf
-
"Lumpy Price Adjustments: A Microeconometric Analysis", Emmanuel Dhyney, Catherine Fuss, M. Hashem Pesaran, Patrick Sevestre April, 2007, Revised August 2008
Abstract: This paper presents a simple model of state-dependent pricing that allows identification of the relative importance of the degree of price rigidity that is inherent to the price setting mechanism (intrinsic) and that which is due to the price’s driving variables (extrinsic). Using two data sets consisting of a large fraction of the price quotes used to compute the Belgian and French CPI, we are able to assess the role of intrinsic and extrinsic price stickiness in explaining the occurrence and magnitude of price changes at the outlet level. We find that infrequent price changes are not necessarily associated with large adjustment costs. Indeed, extrinsic rigidity appears to be significant in many cases. We also find that asymmetry in the price adjustment could be due to trends in marginal costs and/or desired mark-ups rather than asymmetric cost of adjustment bands.
JEL Classifications: C51, C81, D21
Key Words: Sticky prices, nominal intrinsic and extrinsic rigidities, micro non- linear panels
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp08/LumpyPriceAdjustments14Aug08.pdf
-
"Large Panels with Common Factors and Spatial Correlation", M. Hashem Pesaran and Elisa Tosseti August, 2007, revised May 2010
Abstract: This paper considers methods for estimating the slope coeficients in large panel data models that are robust to the presence of various forms of error cross section dependence. It introduces a general framework where error cross section dependence may arise because of unobserved common effects and/or error spill-over effects due to spatial or other forms of local dependencies. Initially, this paper focuses on a panel regression model where the idiosyncratic errors are spatially dependent and possibly serially correlated, and derives the asymptotic distributions of the mean group and pooled estimators under heterogeneous and homogeneous slope coeficients, and for these estimators proposes non-parametric variance matrix estimators. The paper then considers the more general case of a panel data model with a multifactor error structure and spatial error correlations. Under this framework, the Common Correlated Effects (CCE) estimator, recently advanced by Pesaran (2006), continues to yield estimates of the slope coeficients that are consistent and asymptotically normal. Small sample properties of the estimators under various patterns of cross section dependence, including spatial forms, are investigated by Monte Carlo experiments. Results show that the CCE approach works well in the presence of weak and/or strong cross sectionally correlated errors.
JEL Classifications: C10, C31, C33
Key Words: Panels, Common Factors, Spatial Dependence, Common Correlated Effects Estimator.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/PesaranTosetti-31-may-10.pdf
-
"Variable Selection, Estimation and Inference for Multi-period Forecasting Problems", by M. Hashem Pesaran, A. Pick and A. Timmerman. April, 2010
Abstract: This paper conducts a broad-based comparison of iterated and direct multi-period forecasting approaches applied to both univariate and multivariate models in the form of parsimonious factor-augmented vector autoregressions. To account for serial correlation in the residuals of the multi-period direct forecasting models we propose a new SURE based estimation method and modified Akaike information criteria for model selection. Empirical analysis of the 170 variables studied by Marcellino, Stock and Watson (2006) shows that information in factors helps improve forecasting performance for most types of economic variables although it can also lead to larger biases. It also shows that finitesample modifications to the Akaike information criterion can modestly improve the performance of the direct multi-period forecasts.
JEL Classifications: C22, C32, C52, C53
Key Words: Multi-period forecasts, direct and iterated methods, factor augmented VARs
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/pptiterated_24april_2010.pdf
-
"Panels With Nonstationary Multifactor Error Structures" , by G. Kapetanios, M. Hashem Pesaran and T. Yamagata July, 2006, Revised June 2009
Abstract: The presence of cross-sectionally correlated error terms invalidates much inferential theory of panel data models. Recently, work by Pesaran (2006) has suggested a method which makes use of cross-sectional averages to provide valid inference in the case of stationary panel regressions with a multifactor error structure. This paper extends this work and examines the important case where the unobservable common factors follow unit root processes. The extension to the I(1) processes is remarkable on two counts. Firstly, it is of great interest to note that while intermediate results needed for deriving the asymptotic distribution of the panel estimators differ between the I(1) and I(0) cases, the final results are surprisingly similar. This is in direct contrast to the standard distributional results for I(1) processes that radically differ from those for I(0) processes. Secondly, it is worth noting the significant extra technical demands required to prove the new results. The theoretical findings are further supported for small samples via an extensive Monte Carlo study. In particular, the results of the Monte Carlo study suggest that the cross-sectional average based method is robust to a wide variety of data generation processes and has
lower biases than the alternative estimation methods considered in the paper.
JEL Classifications: C12, C13, C33.
Key Words:Cross Section Dependence, Large Panels, Unit Roots, Principal Components, Common Correlated E¤ects.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp09/KPY_CCEunit_130609.pdf
-
"Spatial and Temporal Diffusion of House Prices in the UK", by Sean Holly, M. Hashem Pesaran and Takashi Yamagata. December, 2009
Abstract: This paper provides a method for the analysis of the spatial and temporal diffusion of shocks in a dynamic system. We use changes in real house prices within the UK economy at the level of regions to illustrate its use. Adjustment to shocks involves both a region specific and a spatial effect. Shocks to a dominant region - London - are propagated contemporaneously and spatially to other regions. They in turn impact on other regions with a delay. We allow for lagged effects to echo back to the dominant region. London in turn is influenced by international developments through its link to New York and other financial centers. It is shown that New York house prices have a direct effect on London house prices. We analyse the effect of shocks using generalised spatio-temporal impulse responses. These highlight the diffusion of shocks both over time (as with the conventional impulse responses) and over space.
Key Words: House Prices, Cross Sectional Dependence, Spatial Dependence.
JEL Classifications: C21, C23
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp09/UKhouseprices_December 9 2009.pdf
-
"Predictability of Asset Returns and the Efficient Market Hypothesis", by M. Hashem Pesaran. May, 2010
Abstract: This paper is concerned with empirical and theoretical basis of the Efficient Market Hypothesis (EMH). The paper begins with an overview of the statistical properties of asset returns at di¤erent frequencies (daily, weekly and monthly), and considers the evidence on return predictability, risk aversion and market efficiency. The paper then focuses on the theoretical foundation of the EMH, and show that market efficiency could co-exit with heterogeneous beliefs and individual irrationality so long as individual errors are cross sectionally weakly dependent in the sense defined by Chudik, Pesaran, and Tosetti (2010). But at times of market euphoria or gloom these individual errors are likely to become cross sectionally strongly dependent and the collective outcome could display significant departures from market e¢ ciency. Market efficiency could be the norm, but it is likely to be punctuated with episodes of bubbles and crashes. The paper also considers if market inefficiencies (assuming that they exist) can be exploited for profit.
JEL Classifications: G12, G14
Key Words: Market Efficiency, Predictability, Heterogeneity of Expectations, Forecast averaging, Equity Premium Puzzle.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/AssetReturnsMEH-31-May-2010.pdf
-
"Weak and Strong Cross Section Dependence and Estimation of Large Panels", by Alexander Chudik, M. Hashem Pesaran and Elisa Tosetti April, 2010
Abstract: This paper introduces the concepts of time-specific weak and strong cross section dependence, and investigates how these notions are related to the concepts of weak, strong and semi-strong common factors, frequently used for modelling residual cross section correlations in panel data models. It then focuses on the problems of estimating slope coefficients in large panels, where cross section units are subject to possibly a large number of unobserved common factors. It is established that the Common Correlated Effects (CCE) estimator introduced by Pesaran (2006) remains asymptotically normal under certain conditions on factors loadings of an infinite factor error structure, including cases where methods relying on principal components fail. The paper concludes with a set of Monte Carlo experiments where the small sample properties of estimators based on principal components and CCE estimators are investigated and compared under various assumptions on the nature of the unobserved common effects.
JEL Classifications: Panels, Strong and Weak Cross Section Dependence, Weak and Strong Factors, Common Correlated E¤ects (CCE) Estimator.
Key Words: C10, C31, C33.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/CPT_StrongWeakCSD_19April10.pdf
-
"Infinite Dimensional VARs and Factor Models", Alexander Chudik and M. Hashem Pesaran. November, 2007, Revised October 2008
Abstract: This paper introduces a novel approach for dealing with the ‘curse of dimensionality’ in the case of large linear dynamic systems. Restrictions on the coeficients of an unrestricted VAR are proposed that are binding only in a limit as the number of endogenous variables tends to infinity. It is shown that under such restrictions, an infinite-dimensional VAR (or IVAR) can be arbitrarily well characterized by a large number of finite-dimensional models in the spirit of the global VAR model proposed in Pesaran et al. (JBES, 2004). The paper also considers IVAR models with dominant individual units and shows that this will lead to a dynamic factor model with the dominant unit acting as the factor. The problems of estimation and inference in a stationary IVAR with unknown number of unobserved common factors are also investigated. A cross section augmented least squares estimator is proposed and its asymptotic distribution is derived. Satisfactory small sample properties are documented by Monte Carlo experiments.
JEL Classifications: C10, C33, C51
Key Words: Large N and T Panels, Weak and Strong Cross Section Dependence, VAR, Global, VAR, Factor Models.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp10/ChudikPesaran_RevisedPaper_22Jan10.pdf
-
"Forecasting Random Walks Under Drift Instability", by M. Hashem Pesaran and Andreas Pick. March, 2008, Revised January 2009
Abstract: This paper considers forecast averaging when the same model is used but estimation is carried out over different estimation windows. It develops theoretical results for random walks when their drift and/or volatility are subject to one or more structural breaks. It is shown that compared to using forecasts based on a single estimation window, averaging over estimation windows leads to a lower bias and to a lower root mean square forecast error for all but the smallest of breaks. Similar results are also obtained when observations are exponentially down-weighted, although in this case the performance of forecasts based on exponential down-weighting critically depends on the choice of the weighting coeficient. The forecasting techniques are applied to 20 weekly series of stock market futures and it is found that average forecasting methods in general perform better than using forecasts based on a single estimation window.
Key Words: Forecast combinations, averaging over estimation windows, exponentially down-weighting observations, structural breaks.
JEL Classifications: C22, C53.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp09/AveWExpW20Jan09.pdf
Abstract: This paper applies the modelling strategy of Garratt, Lee, Pesaran and Shin (2003) to the estimation of a structural cointegrated VAR model that relates the core macroeconomic variables of the Swiss economy to current and lagged values of a number of key foreign variables. We identify and test a long-run structure between the variables. Moreover, we analyse the dynamic properties of the model using Generalised Impulse Response Functions. In its current form the model can be used to produce forecasts for the endogenous variables either under alternative specifications of the marginal model for the exogenous variables, or conditional on some pre-specified path of those variables (for scenario forecasting). In due course the Swiss VECX* model can also be integrated within a Global VAR (GVAR) model where the foreign variables of the model are determined endogenously.
Key Words: Long-run structural vector autoregression.
JEL Classifications: C53, C32.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp08/SwissVECXModel(21Feb08).pdf
-
"A VECX* Model of the Swiss Economy", by Katrin Assenmacher-Wesche and M. Hashem Pesaran. February, 2008
-
"Modelling Volatilities and Conditional Correlations in Futures Markets with a Multivariate t Distribution", Bahram Pesaran and M. Hashem Pesaran June, 2007
Abstract: This paper considers a multivariate t version of the Gaussian dynamic conditional correlation (DCC) model proposed by Engle (2002), and suggests the use of devolatized returns computed as returns standardized by realized volatilities rather than by GARCH type volatility estimates. The t-DCC estimation procedure is applied to a portfolio of daily returns on currency futures, government bonds and equity index futures. The results strongly reject the normal-DCC model in favour of a t-DCC specification. The t-DCC model also passes a number of VaR diagnostic tests over an evaluation sample. The estimation results suggest a general trend towards a lower level of return volatility, accompanied by a rising trend in conditional cross correlations in most markets; possibly reflecting the advent of euro in 1999 and increased interdependence of financial markets.
JEL Classifications: C51, C52, G11
Key Words: Volatilities and Correlations, Futures Market, Multivariate t, Financial Interdependence, VaR diagnostics.
Full Text: http://www.econ.cam.ac.uk/emeritus/mhp1/wp2007/PP_TDCC(28Jun07).pdf
Cannot connect to database